针对大规模结构化预测问题的模型常常容易面临过拟合问题。过拟合问题是指模型在训练集上错误率很低,但在测试数据集上错误率偏高。要解决模型过拟合问题,我们需要对模型引入惩罚项以降低模型复杂度。具体有以下常用方法:
- 权重正则化
- 结构正则化
- 最大值约束
- Dropout
权重正则化
常用的权重正则化方法是在损失函数中加上 L1 惩罚项或者 L2 惩罚项:
\[min\space loss(x,y,w) + \lambda regularizer(w)\]其中\(loss\space (x,y,w)\) 代表原有的损失函数。\(regularizer(w)\) 代表权重正则化的项,而 \(\lambda\) 则是正则 化的系数。若正则化项为 L1 正则项,则
\[regularizer(w) = ||w||\]若正则化项为 L2 正则项,则
\[regularizer(w) = \frac{1}{2}||w||^{2}\]在神经网络训练过程中,L2正则化是最普遍使用的。它的原理是在损失函数中对权重参数施加一个权重平方的惩罚项,也就是说针对每一项权重\(w\)均要添加 \(\frac{1}{2}\lambda ||w||^{2}\)的项式。\(\lambda\)为正则化系数。前面\(\frac{1}{2}\)的作用是能够把惩罚项关于权重\(w\)的梯度简化成 \(\lambda w\)替代\(2 \lambda w\)。
L1正则化也是被广泛应用的避免模型过拟合的方法。它是在损失函数上针对所有权重\(w\)都添加一\(\lambda ||w||\)惩罚项。 权重正则化L1和L2也可以组合使用对模型加以约束。
结构化正则化
它的思想是将复杂的模型结构分解为简单的结构。有两种实现方式:一种是先提取特征,再进行结构分解;另一种方法是仅分解输出序列的结构, 保留输入序列的信息。
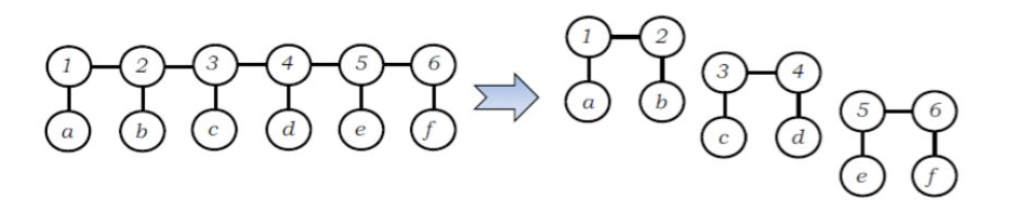
最大值约束
该正则化方式分成两种方面,一种是对参数权重\(w\)的约束,另外一种是对损失函数梯度值的约束。例如将每一个神经元权重设置成不超过\(c\)的常数,一般来说\(c\)通常取值为3-5。这种方法还带来一种优势是避免的模型梯度爆炸问题。
Dropout
Dropout思想也较为容易理解,在模型训练阶 段,部分神经元不参与前向和后向传递,通过随机减少参数的方法来减低模型的复杂度,减少模型过拟合的风险。
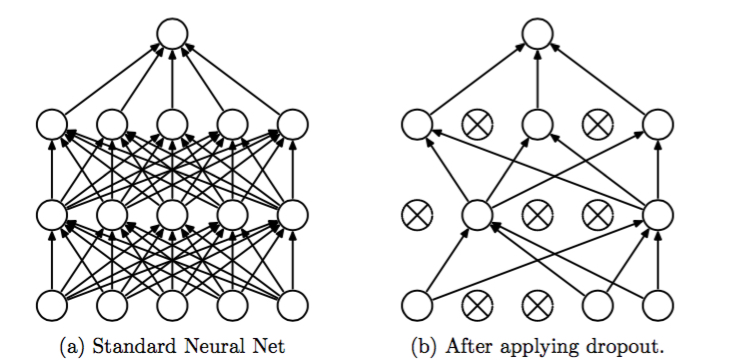
总结
模型过拟合是大规模结构化学习中常见的问题之一。
权重正则化、结构正则化和 Dropout是有效解决过拟合问 题的常见手段。权重正则化通过引入惩罚项来避免过拟合;结构正则化则是通过直接降低模型结构的复杂度来避免过拟合;Dropout 通过随机减少神经网络的参数来解决过拟合的问题。
通过理论分析可以知道,复杂的结构训练出的模型会得到低的经验风险,但是可能导致高的过拟合的风险。而简单的结构训练出的模型有高的经验风险,但是过拟合的风险相对较低,因此我们需要找到一个合适的结构复杂度来平衡二者之间的关系。