本文详细介绍了RAPTOR、SELF-RAG和CRAG等优化算法,同时对一些RAG工程实践中的优化方法做了介绍,如文本切割、Query重写、混合检索等。
Table of Contents
RAG是一种结合检索系统和生成模型的技术,通过引入外部知识提高语言生成的准确性和相关性,特别适用于需要专业知识或大量背景信息的场景。在实际落地时,RAG应用存在一些问题,如缺少垂直领域知识、存在幻觉和应用门槛、以及存在重复建设等。本文详细介绍了RAPTOR、SELF-RAG和CRAG等优化算法,同时对一些RAG工程实践中的优化方法做了介绍,如文本切割、Query重写、混合检索等。
Query优化
- 分析Query结构(分词、NER)
分词:将查询分解成单独的词语或词组,便于进一步处理。
NER(命名实体识别):识别查询中的命名实体,如人名、地名、组织等,有助于理解查询的具体内容。
-
纠正Query错误(纠错) 对查询中的拼写错误或语法错误进行自动纠正,以提高检索的准确性。
-
联想Query语义(改写) 对查询进行语义改写,使其更具表达力和检索效果。
HyDE:一种基于上下文的联想查询改写方法,利用现有信息生成更有效的查询。
RAG-Fusion:结合检索和生成的技术,进一步增强查询的表达能力。
- 扩充Query上下文(省略补全、指代消解) 对查询进行上下文扩展,补全省略的内容或解析指代关系,使查询更完整和明确。

检索模式
混合检索(Hybrid Retrieval)是一种结合了稀疏检索(Sparse Retrieval)和稠密检索(Dense Retrieval)的策略,旨在兼顾两种检索方式的优势,提高检索的效果和效率。
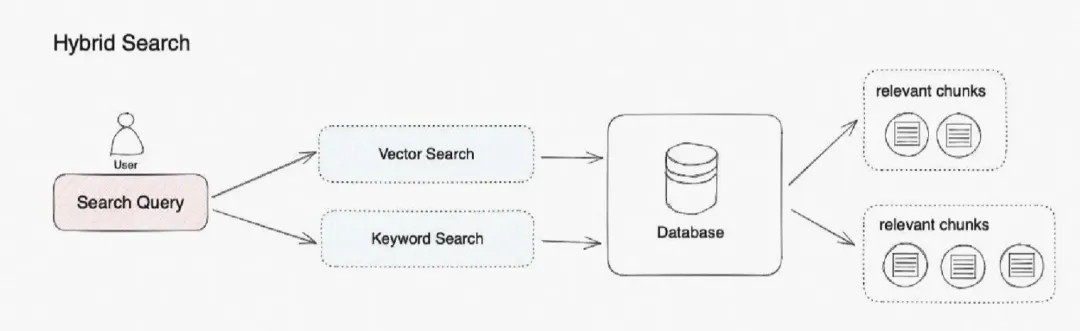
1.稀疏检索(Sparse Retrieval):这种方法通常基于倒排索引(Inverted Index),对文本进行词袋(Bag-of-Words)或TF-IDF表示,然后按照关键词的重要性对文档进行排序。稀疏检索的优点是速度快,可解释性强,但在处理同义词、词语歧义等语义问题时效果有限。
2.稠密检索(Dense Retrieval):这种方法利用深度神经网络,将查询和文档映射到一个低维的稠密向量空间,然后通过向量相似度(如点积、余弦相似度)来度量查询与文档的相关性。稠密检索能更好地捕捉语义信息,但构建向量索引的成本较高,检索速度也相对较慢。
查询转换
对用户查询query进一步修改。
- 重新表述(Rephrasing) :如果 RAG 系统找不到 query 的相关上下文,可以让 LLM 重新表述 query 并重新提交。
- HyDE:HyDE策略在接收 query 后,先生成假设的回复,然后将两者都同时用于嵌入向量(embedding)的查找。研究显示这种方法可以显著提高 RAG 系统的性能。
- 子查询(Sub-queries) :对复杂的 query 进行分解,往往能让 LLM 的效果更好。可以将这一点纳入 RAG 系统中,将 query 分解为多个问题。
查询路由
通常情况下,拥有多个索引(index)是非常有用的。当 query 进来时,就可以将其路由到相应的索引。例如,可以有一个索引处理摘要问题(summarization questions),另一个处理那些直接寻求明确答案的问题(pointed questions),还有一个索引适用于需要考虑时间因素才能得到准确答案的问题。如果试图针对所有这些行为优化一个索引,最终会影响索引在所有这些行为中的表现。 相反,你可以将 query 路由到适当的索引。
Chunking优化
基本方法
-
文本切割是优化语言模型应用性能的关键步骤。
-
切割策略应根据数据类型和语言模型任务的性质来定制。
-
传统的基于物理位置的切割方法(如字符级切割和递归字符切割)虽简单,但可能无法有效地组织语义相关的信息。
-
语义切割和基因性切割是更高级的方法,它们通过分析文本内容的语义来提高切割的精确度。
-
使用多向量索引可以提供更丰富的文本表示,从而在检索过程中提供更相关的信息。
-
工具和技术的选择应基于对数据的深入理解以及最终任务的具体需求。
五种文本切割的层次:
- 字符级切割: 简单粗暴地按字符数量固定切割文本。
- 递归字符切割: 考虑文本的物理结构,如换行符、段落等,逐步递归切割。
- 文档特定切割: 针对不同类型的文档(如Markdown、Python代码、JavaScript代码和PDF),使用特定的分隔符进行切割。
- 语义切割: 利用语言模型的嵌入向量来分析文本的意义和上下文,以确定切割点。
- 基因性切割: 创建一个Agent,使用Agent来决定如何切割文本,以更智能地组织信息。
算法优化
RAPTOR(树形递归概要生成)
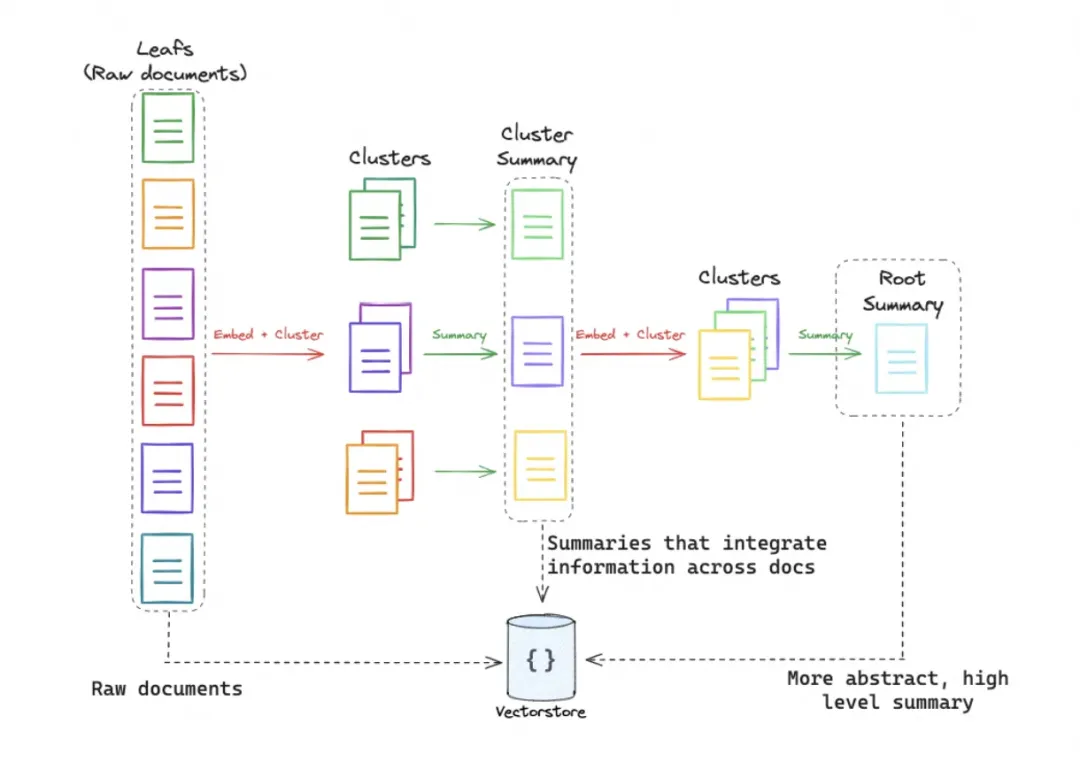
传统的RAG方法通常仅检索较短的连续文本块,这限制了对整体文档上下文的全面理解。RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)通过递归嵌入、聚类和总结文本块,构建一个自底向上的树形结构,在推理时从这棵树中检索信息,从而在不同抽象层次上整合来自长文档的信息。
- 树形结构构建:
- 文本分块:首先将检索语料库分割成短的、连续的文本块。
- 嵌入和聚类:使用SBERT(基于BERT的编码器)将这些文本块嵌入,然后使用高斯混合模型(GMM)进行聚类。
- 摘要生成:对聚类后的文本块使用语言模型生成摘要,这些摘要文本再重新嵌入,并继续聚类和生成摘要,直到无法进一步聚类,最终构建出多层次的树形结构。
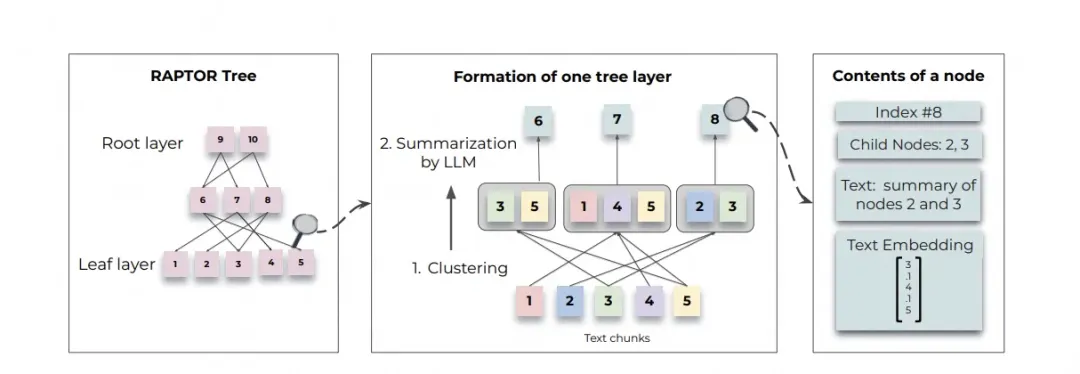
- 查询方法:
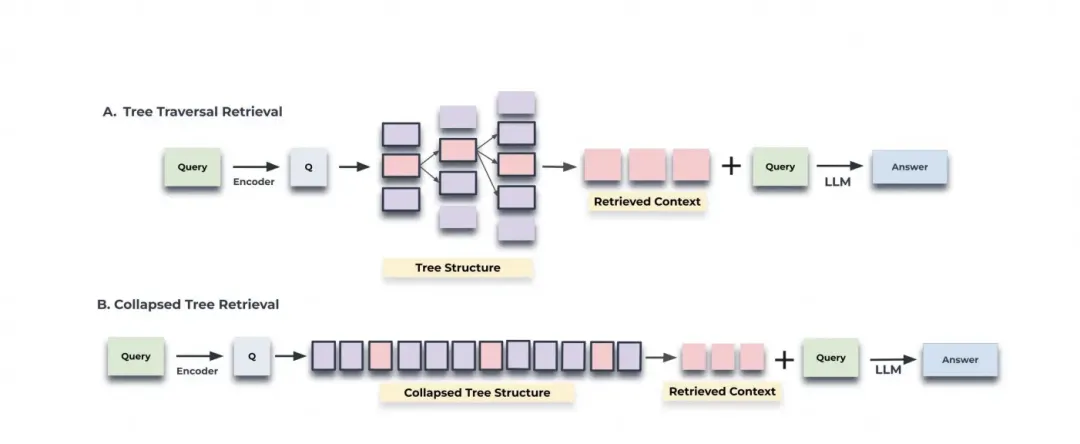
- 树遍历:从树的根层开始,逐层选择与查询向量余弦相似度最高的节点,直到到达叶节点,将所有选中的节点文本拼接形成检索上下文。
- 平铺遍历:将整个树结构平铺成一个单层,将所有节点同时进行比较,选出与查询向量余弦相似度最高的节点,直到达到预定义的最大token数。
SELF-RAG
SELF-RAG(自反思检索增强生成)是一种新框架,通过让语言模型在生成过程中进行自我反思,来提高生成质量和事实正确性,同时不损失语言模型的多样性。
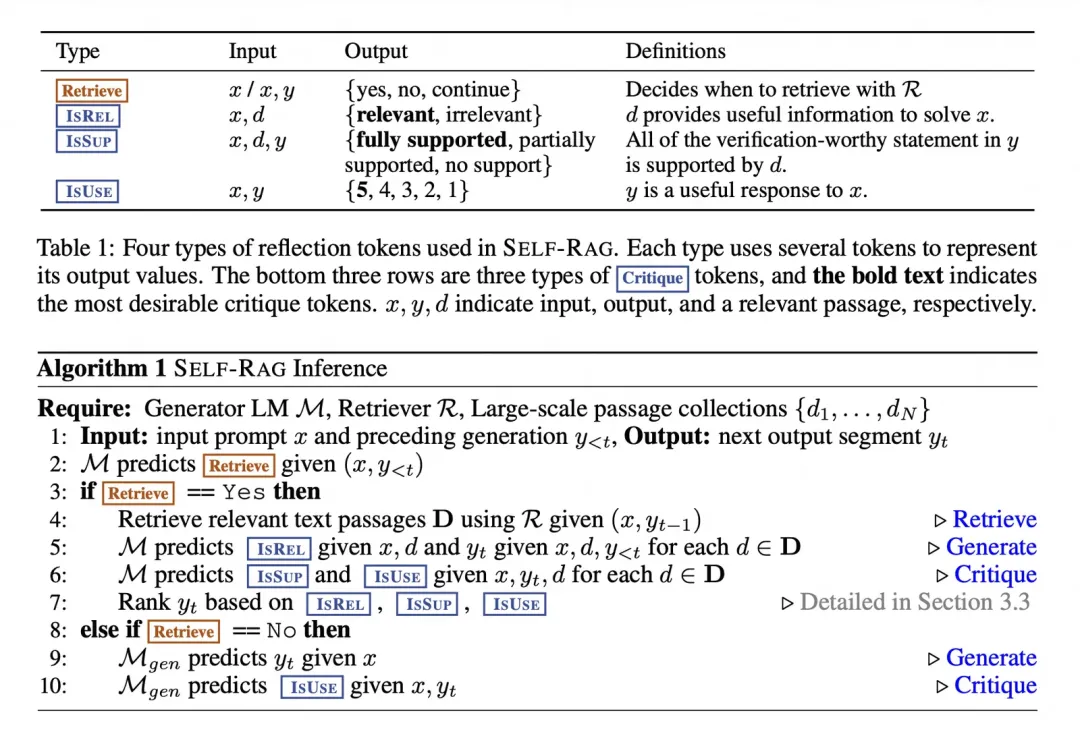
输入:接收输入提示 ( x ) 和之前生成的文本 (y<t) ,其中(y-t)是模型基于本次问题生成的文本?
检索预测:模型 ( M ) 预测是否需要检索(Retrieve),基于 ( (x, y<t) )。
检索判断:
如果 ( Retrieve ) == 是:
1. 检索相关文本段落:使用 ( R ) 基于 ( (x, y<t) ) 检索相关文本段落 ( D )。
2. 相关性预测:模型 ( M ) 预测相关性 ( ISREL ),基于 ( x ),段落 ( d ) 和 ( y<t ) 对每个 ( d ) 进行评估。
3. 支持性和有用性预测:模型 ( M ) 预测支持性 ( ISSUP ) 和有用性 ( ISUSE ),基于 ( x, y<t, d ) 对每个 ( d ) 进行评估。
4.排序:基于 ( ISREL ), ( ISSUP ), 和 ( ISUSE ) 对 ( y<t ) 进行排序。
如果 ( Retrieve ) == 否:
1. 生成下一个段落:模型 ( M ) 基于 ( x ) 生成 ( y_t )。
2. 有用性预测:模型 ( M ) 预测有用性 ( ISUSE ),基于 ( x, y_t ) 进行评估。
- 传统RAG:先检索固定数量的文档,然后将这些文档结合生成回答,容易引入无关信息或虚假信息。
- SELF-RAG:通过自反思机制,按需检索相关文档,并评估每个生成段落的质量,选择最佳段落生成最终回答,提高生成的准确性和可靠性。
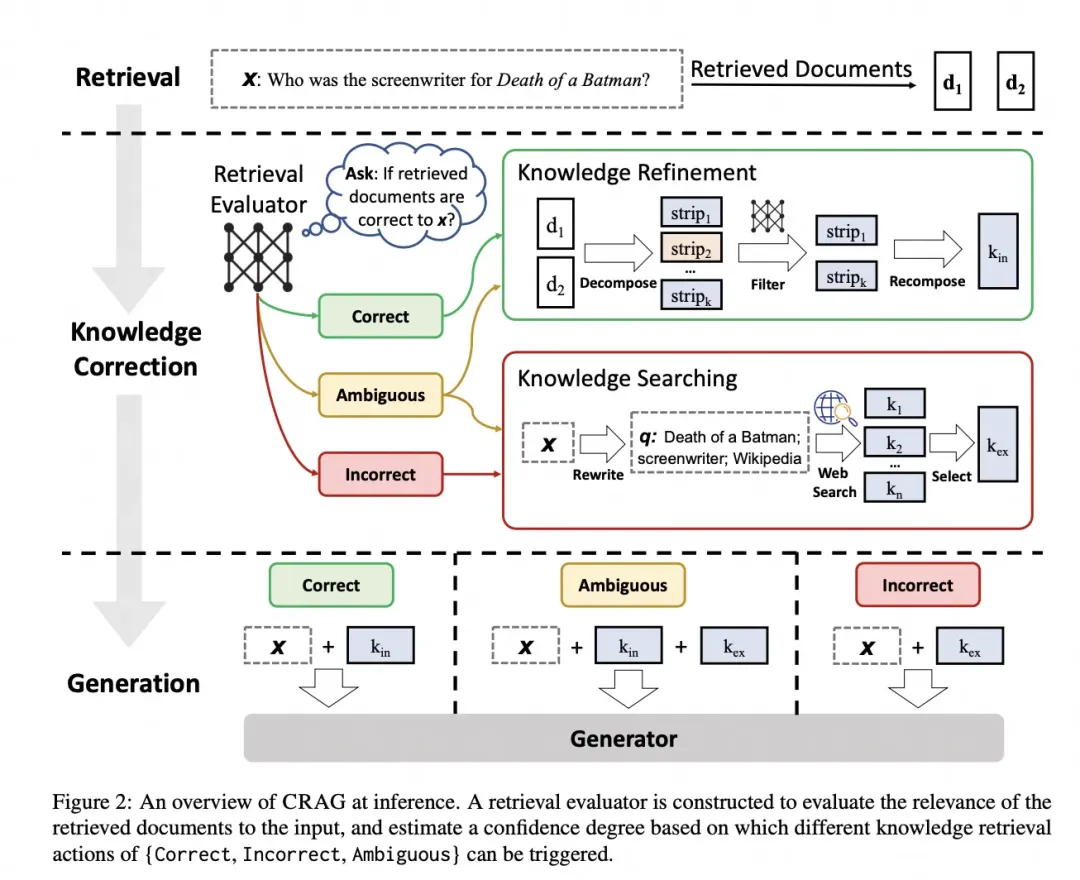
CRAG
纠错检索增强生成(Corrective RetrievalAugmented Generation, CRAG),旨在解决现有大语言模型(LLMs)在生成过程中可能出现的虚假信息(hallucinations)问题。
核心思想:
- 问题背景:大语言模型(LLMs)在生成过程中难免会出现虚假信息,因为单靠模型内部的参数知识无法保证生成文本的准确性。尽管检索增强生成(RAG)是LLMs的有效补充,但它严重依赖于检索到的文档的相关性和准确性。
- 解决方案:为此,提出了纠错检索增强生成(CRAG)框架,旨在提高生成过程的鲁棒性。具体来说,设计了一个轻量级的检索评估器来评估检索到的文档的整体质量,并基于评估结果触发不同的知识检索操作。
具体方法:
1、 输入和输出:
- x 是输入的问题。
- D 是检索到的文档集合。
- y 是生成的响应。
2、 评估步骤:
- scorei 是每个问题-文档对的相关性得分,由检索评估器 E 计算。
- Confidence 是基于所有相关性得分计算出的最终置信度判断。
3、 动作触发:
- 如果置信度为 CORRECT,则提取内部知识并进行细化。
- 如果置信度为 INCORRECT,则进行网络搜索获取外部知识。
- 如果置信度为 AMBIGUOUS,则结合内部和外部知识。
4、 生成步骤:
- 使用生成器 G 基于输入问题 x 和处理后的知识 k 生成响应 y。
关键的组件:
1、检索评估器:
- 基于置信度分数,触发不同的知识检索操作:Correct(正确)、Incorrect(错误)和Ambiguous(模糊)。
2、知识重组算法:
- 对于相关性高的检索结果,设计了一个先分解再重组的知识重组方法。首先,通过启发式规则将每个检索到的文档分解成细粒度的知识片段。
- 然后,使用检索评估器计算每个知识片段的相关性得分。基于这些得分,过滤掉不相关的知识片段,仅保留相关的知识片段,并将其按顺序重组。
3、网络搜索:
- 由于从静态和有限的语料库中检索只能返回次优的文档,因此引入了大规模网络搜索作为补充,以扩展和增强检索结果。
- 当所有检索到的文档都被认为是错误的时,引入网络搜索作为补充知识源。通过网络搜索来扩展和丰富最初获取的文档。
- 输入查询被重写为由关键词组成的查询,然后使用搜索API(如Google Search API)生成一系列URL链接。通过URL链接导航网页,转录其内容,并采用与内部知识相同的知识重组方法,提取相关的网络知识。