由于用户原始查询可能是措辞不准确或缺少语义信息,LLM 难以理解并生成相关的结果,本文介绍了一些重要的Query 重写技术,如HyDE、Query2Doc等。
Table of Contents
概述
由于用户原始查询可能是措辞不准确或缺少语义信息,LLM 难以理解并生成相关的结果。因此,如何优化 query,增强 LLM 对各类 query 信息的精准理解能力,是当前亟待攻克的重要课题。
Query rewriting 是将 queries 和系统中存储的文档的语义空间进行对齐(aligning the semantics of queries and documents)的关键技术。Query重写技术包括以下:
- Hypothetical Document Embeddings,HyDE: 通过 hypothetical documents 对齐 queries 和系统中存储的文档的语义空间。hypothetical documents 并非实际存在的文档,而是虚构文档。
- Rewrite-Retrieve-Read: 提出了一种与传统的检索和阅读顺序不同的框架,侧重于使用 query rewriting 技术。
- Step-Back Prompting: 允许 LLM 从抽象的概念或高层次的信息中进行推理和检索,而不仅仅局限于具体的细节或低层次的信息。
- Query2Doc: 使用少量提示词或相关信息让 LLM 创建 pseudo-documents,然后将这些信息与用户输入的 queries 合并,构建新的 queries 。
- ITER-RETGEN: 提出了一种将前一轮生成的结果与先前 query 相结合的方法。然后检索相关文档并生成新的结果。多次重复这个过程,直到获得最终结果。
HyDE
用户的原始 query 和召回的内容之间不匹配。从工程角度来看,有两个角度可以解决此问题:
- 召回阶段:在用户问题不变的情况下如何更好地理解语义信息,找到更正确的相关文档
- 问题阶段:在后续召回流程不变的情况下,如何使得用于召回的输入更准确,即对原始Query重写。
查询重写(Query Reriting)是调整查询和文档语义的关键技术,当前有很多方法被提出用于解决此问题。这里介绍来自CMU的 Query 重写工作即假设性文档嵌入HyDE 。
基本原理
使用原始用户Query先生成假回答,假回答和真回答虽然可能存在事实错误,但是会比较像,因此能更容易找到相关内容。这里的假回答,就是论文中提到的假设性文档(Hypothetical Document)。
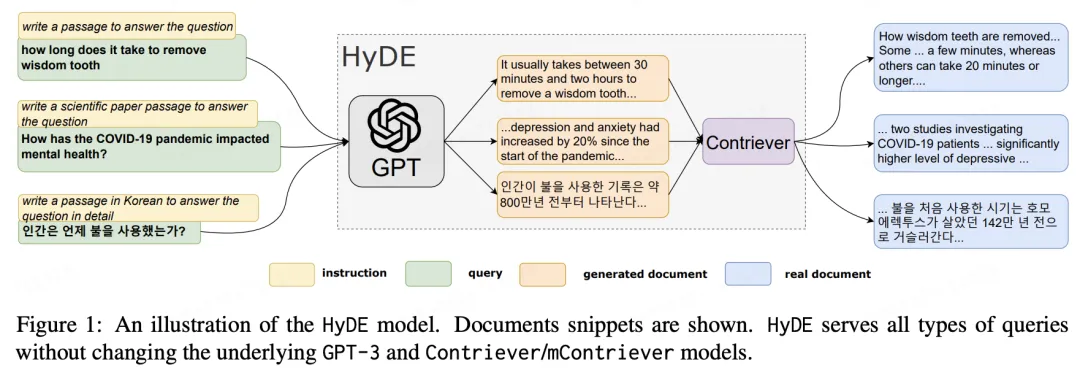
核心步骤:
-
对于用户 query,使用 LLM 生成 $k$个假设性文档(回答)$d_k$,虽然生成的回答可能是错的,但是他们应当类似于真实的文档。此步骤相当于是利用 LLM 对 query 进行解释。
-
将假设性文档进行编码,得到 $f(d_i)$,这里的 $f$实际上就是 embedding,得到了 $k$个向量
-
计算向量的平均值,这里有两种方法,一种是对 $k$ 个向量 进行平均,另一种是将查询query 也作为一个可能的假设,求平均,即:
\[v = \frac{1}{k+1}\left[\sum_{i=0}^{k}f(d_i) + f(q)\right]\]
4.按照 RAG 的思路,以$v$向量作为 embedding,进行召回匹配。
从其思想上看,具备以下的效果:
通过实验对比,证明了 HyDE 方法可以显著提高 RAG 的回答效果。当然,失败的例子也是有不少的,可以参考这个页面:失败 case 失败case。可能是以下原因:
-
当查询在没有上下文的情况下被误解时,HyDE 可能会产生误导
-
对于开放式问题,HyDE 可能会不准
总的来说,HyDE 是一个无监督的方法,可以帮助 RAG 提高效果。但是因为它不完全依赖于 embedding 而是强调问题的答案和查找内容的相似性,也存在一定的局限性。比如如果 LLM 无法理解用户问题,自然不会产生最佳结果,也可能导致错误增加。
Rewrite-retrieve-read
该技术由论文《Query Rewriting for Retrieval-Augmented Large Language Models》提出。该论文认为,在现实世界场景中,用户提交的原始 query 可能并非都适合直接交给 LLM 进行检索。
这篇论文建议我们应该首先使用 LLM 对 queries 进行重写。然后再检索内容和生成模型响应,而非直接从 original query 中检索内容并生成模型响应
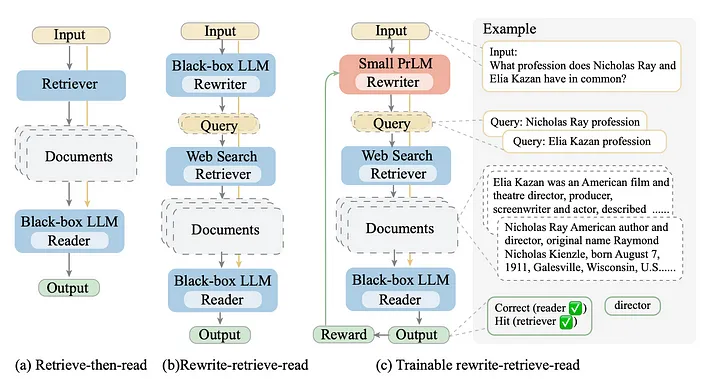
从左到右,(a) 标准的 “retrieve-then-read” 方法,(b) 在 “rewrite-retrieve-read” pipeline 中将 LLM 作为 query rewriter,以及 (c) 在 pipeline 中使用可训练的 rewriter 。
重写提示词如下:
rewrite_template = """Provide a better search query for \
web search engine to answer the given question, end \
the queries with ’**’. Question: \
{x} Answer:"""