Prompt即提示学习,是继预训练+微调范式后众望所归的第四范式。在预训练+微调的范式中我们调整预训练模型来匹配下游任务数据,本质是对预训练学到的众多信息进行重新排列和筛选。
概论
Prompt即提示学习,是继预训练+微调范式后众望所归的第四范式。在预训练+微调的范式中我们调整预训练模型来匹配下游任务数据,本质是对预训练学到的众多信息进行重新排列和筛选。而Prompt是通过引入“提示信息”,让模型回忆起预训练中学过的语言知识,也就是调整下游数据来适配预训练模型,进而把所有NLP任务都统一成LM任务。
Prompt优势
- 微调参数量更小:这几年模型越来越大,连微调都变成了一件很奢侈的事情,而prompt出现提供了新的选择,可以freeze模型只对提示词进行微调
- 小样本场景: 不少Prompt模型是面向zero-shot,few-shot场景设计的
- 多任务范式统一:一切皆为LM!
Prompt微调
微调Prompt范式最大的区别就是prompt模板都是连续型(Embedding),而非和Token对应的离散型模板。核心在于我们并不关心prompt本身是否是自然语言,只关心prompt作为探针能否引导出预训练模型在下游任务上的特定能力。
微调Prompt的范式有以下几个优点
1,性价比高!微调参数少,冻结LM只微调prompt部分的参数 2,无人工参与!无需人工设计prompt模板,依赖模型微调即可 3,多任务共享模型!因为LM被冻结,只需训练针对不同任务的prompt即可。因此可以固定预训练模型,拔插式加入Prompt用于不同下游任务。
Prefix-Tuning
Prefix-Tuning可以理解是CTRL(Conditional Transformer Language有条件的文本生成模型) 1 模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评前面加’Reviews Rating:5.0’,差评前面加’Reviews Rating:1.0’, 政治评论前面加‘Politics Title:’,把语言模型的生成概率,优化成了基于文本主题的条件概率。
Prefix-Tuning进一步把control code优化成了虚拟Token,每个NLP任务对应多个虚拟Token的Embedding(prefix),对于Decoder-Only的GPT,prefix只加在句首,对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。在下游微调时,LM的参数被冻结,只有prefix部分的参数进行更新。不过这里的prefix参数不只包括embedding层而是虚拟token位置对应的每一层的activation都进行更新。
Prompt-tuning
Prompt-tuning是以上prefix-tuning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果~
对比Prefix-tuning,prompt-tuning的主要差异如下:
论文使用100个prefix token作为默认参数,大于以上prefix-tuning默认的10个token,不过差异在于prompt-tuning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调。因此Prompt-tuning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。
P-Tuning
论文同样是连续prompt的设计。不过针对上面提到的Prompt的整体性问题进行了优化。作者认为直接通过虚拟token引入prompt存在两个问题
- 离散性:如果用预训练词表的embedding初始化,经过预训练的词在空间分布上较稀疏,微调的幅度有限,容易陷入局部最优。这里到底是局部最优还是有效信息prior其实很难分清
- 整体性:多个token的连续prompt应该相互依赖作为一个整体,不谋而合了!
- 针对这两个问题,作者使用双向LSTM+2层MLP来对prompt进行表征, 这样LSTM的结构提高prompt的整体性,Relu激活函数的MLP提高离散型。这样更新prompt就是对应更新整个lstm+MLP部分的Prompt Encoder。下面是p-tuning和离散prompt的对比
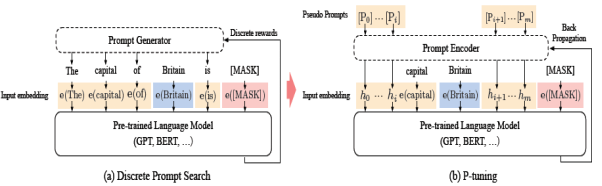
在知识探测任务中,默认是固定LM只微调prompt。效果上P-tuning对GPT这类单项语言模型的效果提升显著,显著优于人工构建模板和直接微调,使得GPT在不擅长的知识抽取任务中可以基本打平BERT的效果。
局限性
-
可解释性差:这是所有连续型prompt的统一问题
- 收敛更慢: 更少的参数想要撬动更大的模型,需要更复杂的空间搜索
- 可能存在过拟合:只微调prompt,理论上是作为探针,但实际模型是否真的使用prompt部分作为探针,而不是直接去拟合任务导致过拟合是个待确认的问题
- 微调可能存在不稳定性:prompt-tuning和p-tuning的github里都有提到结果在SuperGLUE上无法复现的问题
指令微调
现大家对prompt和instruction的定义存在些出入,部分认为instruction是prompt的子集,部分认为instruction是句子类型的prompt。
对比前三章介绍过的主流prompt范式,指令微调有如下特点:
-
面向大模型:指令微调任务的核心是释放模型已有的指令理解能力(GPT3中首次提出),因此指令微调是针对大模型设计的,因为指令理解是大模型的涌现能力之一。而prompt部分是面向常规模型例如BERT
- 预训练:与其说是instruction tunning,更像是instruction pretraining,是在预训练阶段融入多样的NLP指令微调,而非针对特定下游任务进行微调,而之前的promp主要服务微调和zeroshot场景
- multitask:以下模型设计了不同的指令微调数据集,但核心都是多样性,差异化,覆盖更广泛的NLP任务,而之前的prompt模型多数有特定的任务指向
- 泛化性:在大模型上进行指令微调有很好的泛化性,在样本外指令上也会存在效果提升
- 适用模型:考虑指令都是都是sentence形式的,因此只适用于En-Dn,Decoder only类的模型。而之前的prompt部分是面向Encoder的完形填空类型
In-context learning
类比学习,上下文学习或者语境学习。有one-shot和few-shot两种方案,对应不同的增强Prompt的构建方式。随着模型参数量级的提升,few-shot,one-shot带来的效果提升更加显著。
zero-shot: Prompt为任务描述
Translate English to French: cheese =>
one-shot: Prompt Augmentation,任务描述+一个带答案的样本
Translate English to French: sea otter =>loutre de mer cheese =>
few-shot: Prompt Augmentation,任务描述+多个带答案的样本
Translate English to French: sea otter =>loutre de mer peppermint => menthe poivrée plush girafe =>girafe peluche cheese =>
对于Prompt Augmentation带来的效果提升,个人感觉in-context这个词的使用恰如其分,就是带答案的样本输入其实做了和任务描述相似的事情,也就是让待预测的输入处于和预训练文本中任务相关语料相似的上下文。带答案的样本比任务描述本身更接近自然的上下文语境。
In-context learning学习要点
不针对不同的prompt会得到显著不同的结果,Ref6的论文更深入的探究了in-context具体提供了哪些信息,作者定位到以下4类信息
- 输入标签的对应关系: 把样本标签改成错误标签,模型效果下降有限
- 标签分布:把标签改成随机单词,模型效果有显著下降
- 输入分布:在prompt中加入领域外文本,模型效果有显著下降
- 输入输出格式:改变双输入格式,在prompt中只保留标签或者只保留输入,模型效果都会有显著下降
Lora
LoRA的原理比较简单,原始全量微调其实就是在原始模型参数上通过微调加入增量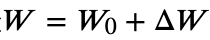 ,那我们可以通过冻结原始参数Wo,并且把增量部分通过低秩分解方式进一步降低参数量级
,那我们可以通过冻结原始参数Wo,并且把增量部分通过低秩分解方式进一步降低参数量级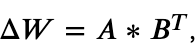 ,原始参数的维度是𝑑∗𝑑, 则低秩分解后的参数量级是2∗𝑟∗𝑑,因为这里的r«d,因此可以起到大幅降低微调参数量级的效果,如下图
,原始参数的维度是𝑑∗𝑑, 则低秩分解后的参数量级是2∗𝑟∗𝑑,因为这里的r«d,因此可以起到大幅降低微调参数量级的效果,如下图
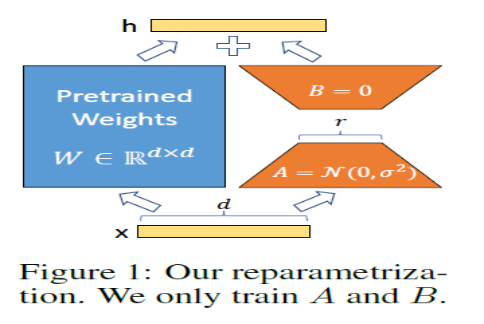
论文测试了在多数场景下适当的LORA微调和全量微调的效果不相上下。一个可能原因是INTRINSIC DIMENSIONALITY论文中提出,虽然语言模型整体参数空间很大,但具体到每个任务其实有各自的隐表征空间(intrisic dimension),这个隐表征空间的维度并不高, 因此在微调过程中加入低秩分解并不一定会影响微调效果。使用LORA微调有以下几个细节
1,对哪些参数进行微调:基于Transformer结构,LORA只对每层的Self-Attention的部分进行微调,有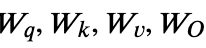 四个映射层参数可以进行微调。消融实验显示只微调𝑊𝑞 效果略差,微调
四个映射层参数可以进行微调。消融实验显示只微调𝑊𝑞 效果略差,微调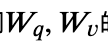 的效果和微调 的效果相似。需要注意不同模型参数名称不同,像chatglm对应的参数名称就是query_key_value
的效果和微调 的效果相似。需要注意不同模型参数名称不同,像chatglm对应的参数名称就是query_key_value
2,Rank的选取:Rank的取值作者对比了1-64,效果上Rank在4-8之间最好,再高并没有效果提升。不过论文的实验是面向下游单一监督任务的,因此在指令微调上根据指令分布的广度,Rank选择还是需要在8以上的取值进行测试。
3,alpha参数:alpha其实是个缩放参数,本质和learning rate相同,所以为了简化我默认让alpha=rank,只调整lr,这样可以简化超参
4,初始化:A和Linear层的权重相同Uniform初始化,B是zero初始化,这样最初的Lora权重为0。所以Lora参数是从头学起,并没有那么容易收敛。
Lora的优点很明显,低参数,适合小样本场景;可以拔插式的使用,快速针对不同下游任务训练不同的lora权重;完全没有推理延时,这个在后面代码中会提到推理时,可以预先把lora权重merge到原始权重上。
但Lora微调虽好,个人在尝试中感受到的局限性就是adapter类的微调方案可能更适合下游单一任务类型/生成风格。至于是否适合作为通用指令微调的解决方案,有个问题我也没有搞懂,就是通用的指令样本是否真的有统一的低秩空间表征?这个表征又是什么含义?因为指令微调阶段的样本其实是混合的多任务指令样本,这种情况下lora是否合适,感觉需要更全面的评估。
https://github.com/ymcui/Chinese-LLaMA-Alpaca https://www.cnblogs.com/gogoSandy/p/17363983.html https://cloud.tencent.com/developer/inventory/30472/article/2237259 https://mp.weixin.qq.com/s/xpbJ6qjLpp1IO5WEvTwKMQ