LLaMA是Anthropic推出的多语言大型语言模型,采用类GPT的transformer架构,但相比GPT更高效,计算资源需求更低。总体而言,LLaMA通过更高效的模型设计,实现了多语言理解的高性能计算,降低了资源门槛,为语言模型的应用普及提供了可能。
背景
什么是LLaMA
- 参数量有四档:7/13/33/65亿,最低那档据说24g显存的显卡可以跑,7亿的LLaMA用了1万亿token进行训练,最大模型则用了1.4万亿。
- 用了万亿个token进行训练(所有数据均来自公开数据集)
- 性能和175亿参数的GPT-3相当
模型类型
| 模型 | 训练方法 |
|---|---|
| Bert系列 | 自编码(AutoEncoder) |
| GPT、LLaMA | 自回归(AutoRegression) |
| T5、BART | Seq2Seq |
数据集
Common Crawl大规模的网络文本数据集(公开的)和其他开源数据集,具体如下图:
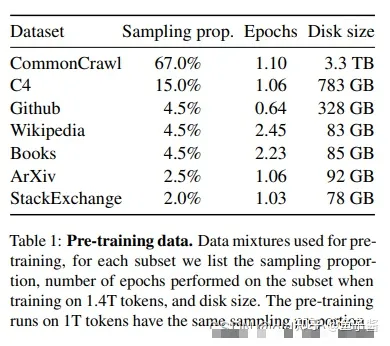
Common Crawl
Common Crawl是一个公开的网络文本数据集,它包含了从2008年开始收集的数千亿个网页的原始数据(包括JS脚本)、元数据和文本提取。LLaMA只取了2017-2020的数据,并进行了一些预处理,来确保数据的质量要求:
- 使用 fastText 线性分类器执行语言识别去掉非英语页面
- 使用 n-gram 语言模型过滤低质量内容
This process deduplicates the data at the line level, performs language identification with a fastText linear classifier to remove non-English pages and filters low quality content with an n-gram language model. In addition, we trained a linear model to classify pages used as references in Wikipedia v.s. randomly sampled pages, and discarded pages not classified as references.
从原文看,作者还做了一个分类器,把没有在维基百科中引用的随机内容页面过滤掉,简单说就是一个页面上的内容如果没有一个单词出现在维基百科中,说明这个页面内容是无意义的,应该去掉。
C4
C4数据集是一个巨大的、清洗过的Common Crawl网络爬取语料库的版本。
文章对C4进行了一些不同的预处理,因为作者观察到使用不同的预处理可以提高性能。
C4 的预处理也包含去重和语言识别步骤:上一个数据集处理区别在于质量过滤,它主要依赖于启发式方法,例如对网页中标点符号的过滤、或者限制单词和句子的数量。
整个数据涵盖的面很广:通用语料、书籍、论文、代码、论坛、不同语言。
作者对数据进行使用了字节对编码(BPE,byte-pair encoding)算法完成token化。作者将所有数字分割成单个数字,并回退到字节来分解未知的UTF-8字符。
最终得到大约1.4T的token,对于训练数据,每个token只使用一次(Wikipedia和Books是用了两个epochs)。
设计细节
Pre-normalization
为了提高训练稳定性,作者对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。注意看Transformer中黄色方块(Add & Norm)部分,都是在输出部分的,现在把这个操作调整到前面对输入进行Norm操作。
文章使用了 Zhang B, Sennrich R. Root mean square layer normalization RMSNorm归一化方法
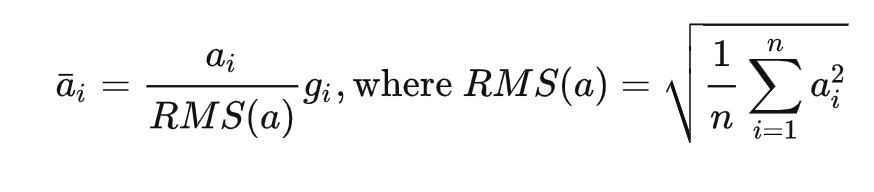
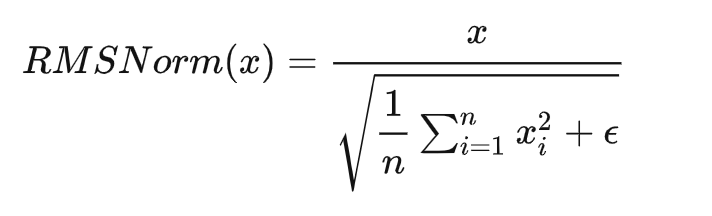
其中,x是输入向量,n是向量的长度,ϵ是一个小常数,用于避免分母为零
SwiGLU
作者用 Shazeer (2020)(https://arxiv.org/pdf/2002.05202.pdf)引入的 SwiGLU 激活函数代替 ReLU 非线性激活函数,提高性能。
-
SwiGLU 激活函数的收敛速度更快,效果更好。
- SwiGLU 激活函数和 ReLU 都拥有线性的通道,可以使梯度很容易通过激活的units,更快收敛。
- SwiGLU 激活函数相比 ReLU 更具有表达能力。
- SwiGLU激活函数的收敛速度更快,这是因为它在计算过程中使用了门控机制,可以更好地控制信息的流动。公式如下:
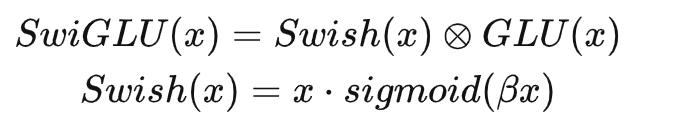
Rotary Embeddings
作者使用rotary positional embeddings (RoPE)(https://arxiv.org/pdf/2104.09864.pdf)来替换原理的绝对位置向量(absolute positional embeddings)。
关于绝对位置向量和相对位置向量看下面例子。
「绝对位置向量」(Bert,原版的Transformer都用的这个):
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 今天 | 天气 | 还 | 不错 |
「相对位置向量」(XLNet用的这个):
| -2 | -1 | 0 | 1 |
|---|---|---|---|
| 今天 | 天气 | 还 | 不错 |
「关于RoPE旋转对称性:」
旋转对称性是指物体在旋转后仍然具有相同的性质。例如,一个正方形在旋转90度后仍然是一个正方形,因此具有旋转对称性。对于NLP来说,旋转对称性指的是序列中的某些部分可以通过旋转变换得到其他部分。
例如,在机器翻译任务中,源语言句子和目标语言句子之间存在一定的对称性。这意味着我们可以通过将源语言句子旋转一定角度来得到目标语言句子。
上面讲的两种表示方式仅仅表达了词在句子中出现的顺序,没有嵌入对称信息。
RoPE可以更好地处理序列中的旋转对称性。在传统的位置编码方法中,位置信息只是简单地编码为一个向量,而没有考虑到序列中的旋转对称性。而旋转位置嵌入则将位置信息编码为一个旋转矩阵,从而更好地处理了序列中的旋转对称性。
优化器
使用AdamW优化器(Loshchilov和Hutter,2017)训练模型,超参数设置如下:β1 = 0.9,β2 = 0.95。 我们使用余弦学习率衰减计划,使得最终学习率等于最大学习率的10%。我们使用权重衰减weight decay为0.1 和梯度裁剪gradient clipping为1,warmup steps 设置2000,并根据模型大小设置学习率和batch大小。
总结关键点:
- 优化器:AdamW
- 超参数:β1=0.9,β2=0.95
- 学习率:余弦衰减到最大值的10%
- 权重衰减:0.1
- 梯度裁剪:1.0
- 热身步数:2000