本文介绍了GraphRAG通过引入知识图谱技术,改进了传统RAG的不足。它通过三元组抽取、子图召回和子图上下文生成,提供了更准确的知识检索和生成。
Table of Contents
概述
检索增强生成RAG技术旨在把信息检索与大模型结合,以缓解大模型推理“幻觉”的问题。RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。更进一步地,RAG的整体链路还可以与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)等技术结合,构成更广义的RAG问答链路。
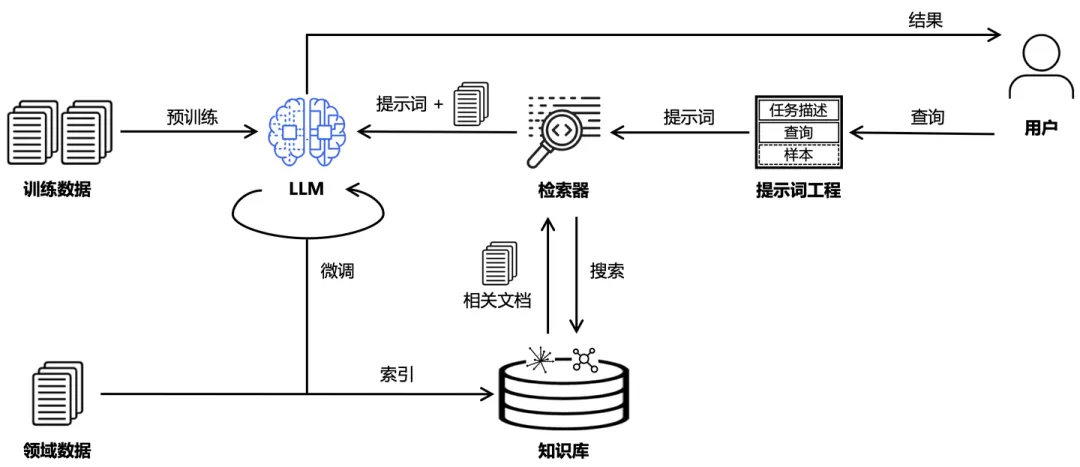
传统RAG功能模块
传统RAG的核心链路分为三个阶段:
- 索引(向量嵌入):通过Embedding模型服务实现文档的向量编码,写入向量数据库。
- 检索(相似查询):通过Embedding模型服务实现查询的向量编码,使用相似性查询(ANN)实现topK结果搜索。
- 生成(文档上下文):Retriver检索的结果文档作为上下文和问题一起提交给大模型处理。
传统RAG希望通过知识库的关联知识增强大模型问答的上下文以提升生成内容质量,但也存在诸多问题。
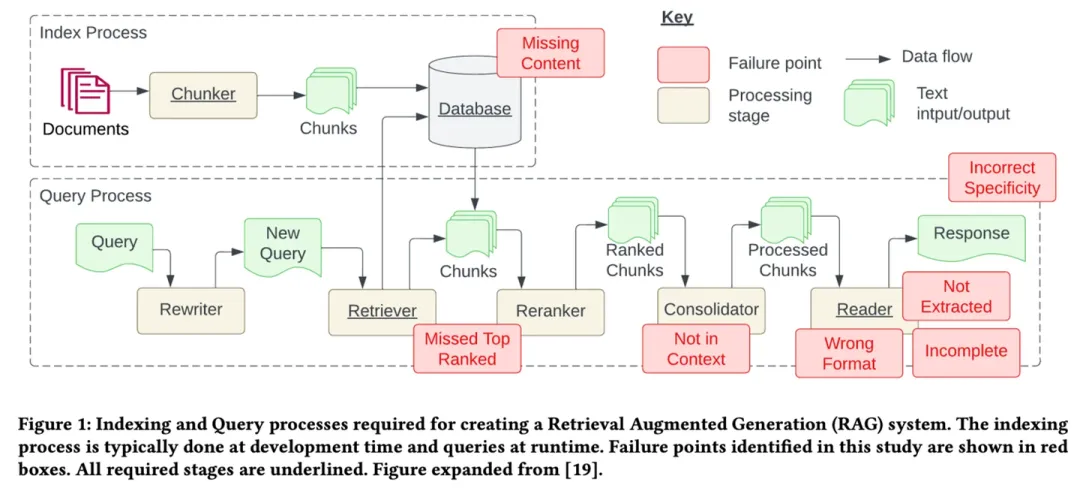
传统RAG面临的问题
一般来讲,传统RAG的存在以下7个问题:
-
知识库内容缺失:现有的文档其实回答不了用户的问题,系统有时被误导,给出的回应其实是“胡说八道”,理想情况系统应该回应类似“抱歉,我不知道”。
-
TopK截断有用文档:和用户查询相关的文档因为相似度不足被TopK截断,本质上是相似度不能精确度量文档相关性。
-
上下文整合丢失:从数据库中检索到包含答案的文档,因为重排序/过滤规则等策略,导致有用的文档没有被整合到上下文中。
-
有用信息未识别:受到LLM能力限制,有价值的文档内容没有被正确识别,这通常发生在上下文中存在过多的噪音或矛盾信息时。
-
提示词格式问题:提示词给定的指令格式出现问题,导致大模型/微调模型不能识别用户的真正意图。
-
准确性不足:LLM没能充分利用或者过度利用了上下文的信息,比如给学生找老师首要考虑的是教育资源的信息,而不是具体确定是哪个老师。另外,当用户的提问过于笼统时,也会出现准确性不足的问题。
-
答案不完整:仅基于上下文提供的内容生成答案,会导致回答的内容不够完整。比如问“文档 A、B和C的主流观点是什么?”,更好的方法是分别提问并总结。
总的来看:
- 问题1-3:属于知识库工程层面的问题,可以通过完善知识库、增强知识确定性、优化上下文整合策略解决。
- 问题4-6:属于大模型自身能力的问题,依赖大模型的训练和迭代。
- 问题7:属于RAG架构问题,更有前景的思路是使用Agent引入规划能力。
GraphRAG
相比于传统的基于Vector格式的知识库存储,GraphRAG引入了知识图谱技术,使用图社区摘要解决总结性查询任务的问题。基于知识图谱,可以为RAG提供高质量的上下文,以减轻模型幻觉。
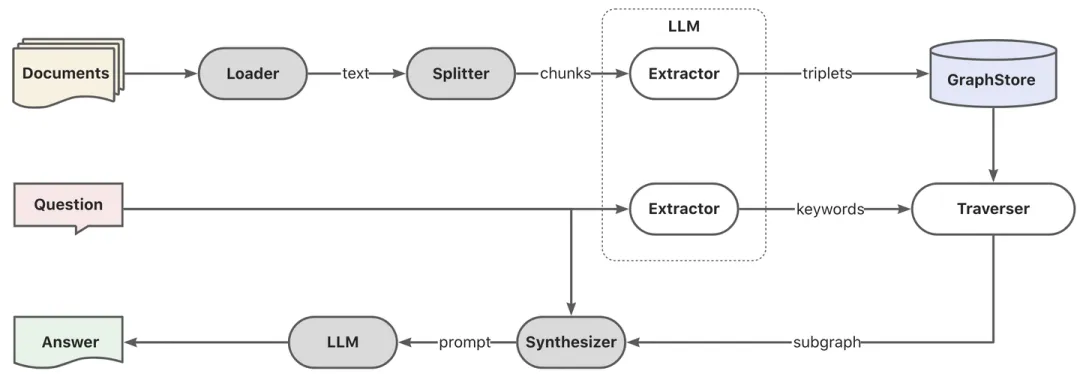
GraphRAG功能模块
Graph RAG的核心链路分如下三个阶段:
- 索引(三元组抽取):通过LLM服务实现文档的三元组提取,写入图数据库。
- 检索(子图召回):通过LLM服务实现查询的关键词提取和泛化(大小写、别称、同义词等),并基于关键词实现子图遍历(DFS/BFS),搜索N跳以内的局部子图。
- 生成(子图上下文):将局部子图数据格式化为文本,作为上下文和问题一起提交给大模型处理。