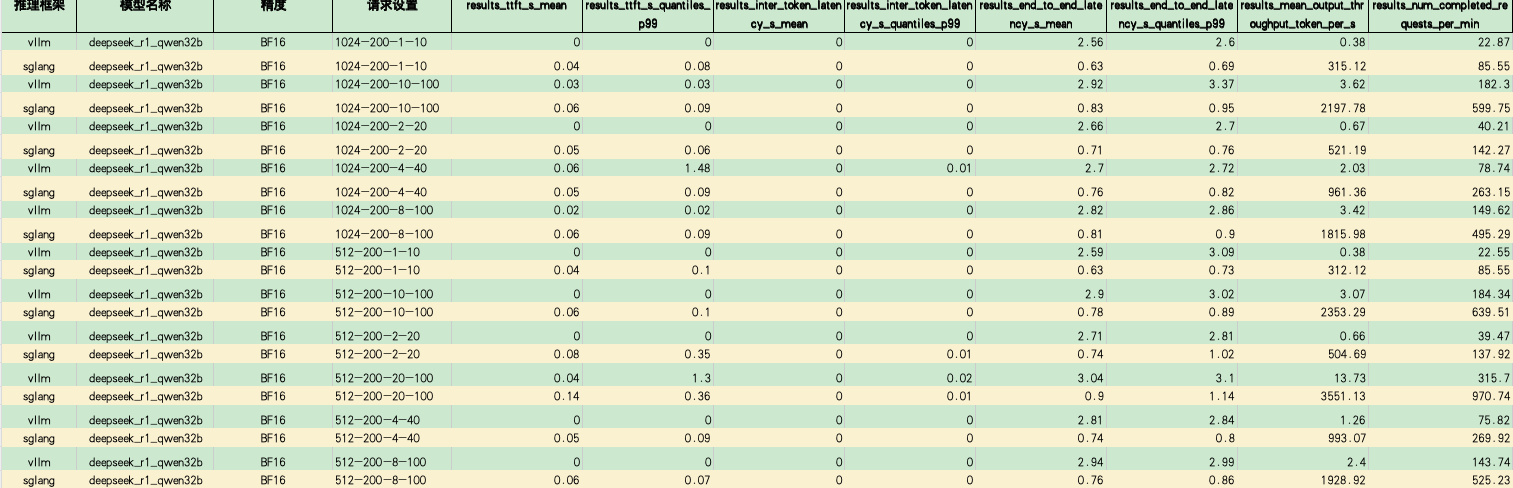
使用SGLang推理框架部署DeepSeek-R1-Distill-Qwen-32B大模型,并与vLLM部署同类服务性能对比。
Table of Contents
模型演化
DeepSeek-V3在V2的基础上,通过引入新的架构和训练策略,进步提升模型的性能,同时降低训练成本。
核心创新点:
-
DeepSeekMoE:一种高效的混合专家模型架构,使用更细粒度的专家,并隔离部分专家作为共亨专家
-
MLA多头潜在注意力机制:通过低秩压缩减少KV缓存,提高推理效率。
-
无辅助损失的负载均衡策略:通过引入偏置项动态调整专家负载,避免了传统辅助损失带来的性能损失。
-
多Token预测(MTP):在每个位置预测多个未来的token,增加训练信号,提高模型的数据效率。
-
FP8混合精度训练框架:首次验证了FP8训练在超大规模模型上的可行性和有效性。
-
高效的训练框架:通过DualPipe算法和优化的通信内核,实现了近乎零开销的跨节点通信。
DeepSeek R1 Zero
作为R1的无SFT版本,R1-Zero使用 DeepSeek-V3-Base 作为基础模型,直接使用 GRPO进行强化学习来提升模型的推理(Reasoning)性能, 根据准确度和格式进行训练奖励。
R1-Zero的训练过程具有重要意义:
-
在大模型训练领域,SFT 需要高质量的人工标注数据(标注过程一般需要很长周期、成本高,且可能因标记者的偏好而引入潜在偏差)。
- 复杂的推理任务可能超出了普通人类的能力。无SFT的纯强化学习方法也许可以使模型能够涌现出超越传统人类思维上限的超级推理能力。
- 无SFT的纯强化学习不依赖于显式标注,允许模型使用非自然语言表征方法进行“思考”,从而具有超越自然语言进行逻辑推理的潜力。
奖励的计算方式在很大程度上决定了强化学习训练的效果。DeepSeek-R1-Zero 的基于规则的奖励系统包括:
-
准确度奖励(Accuracy rewards)。评估响应是否正确。
-
格式奖励(Format rewards)。奖励模型将其思考过程置于“
”和“ ”标签之间。
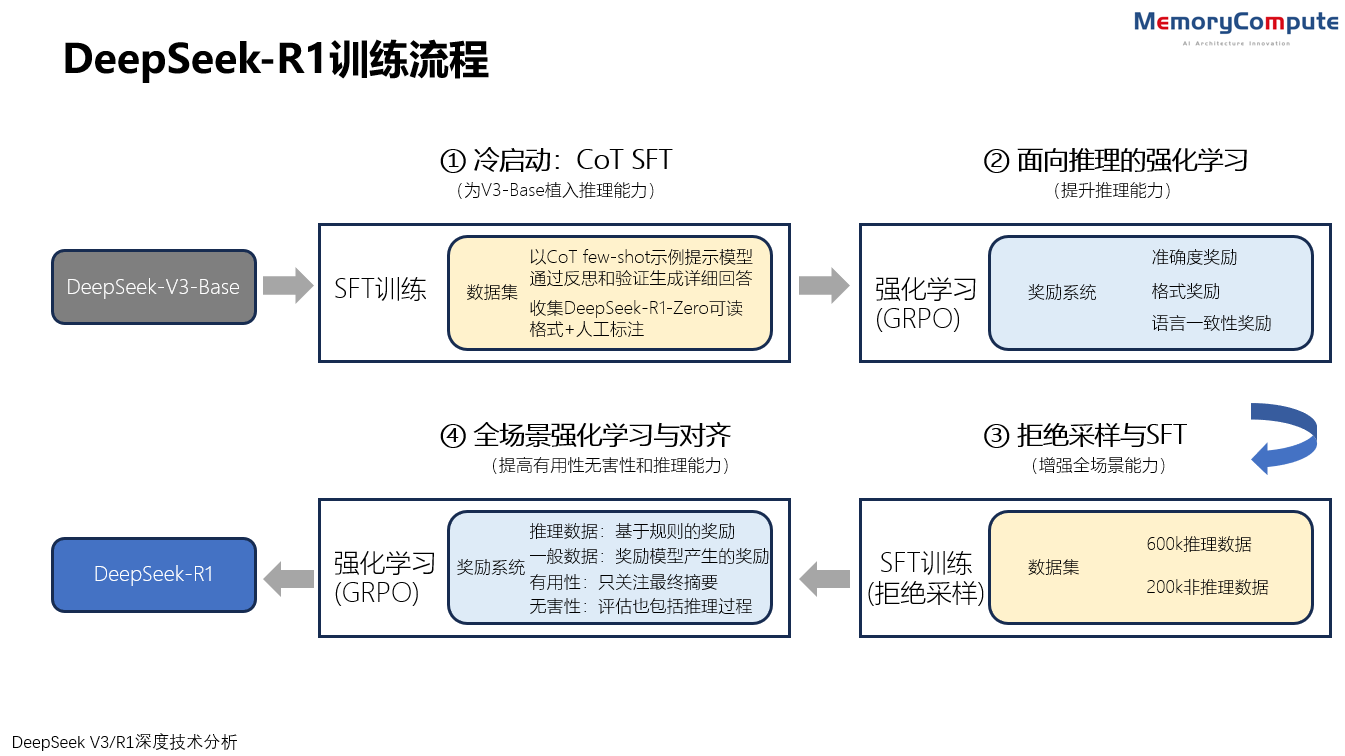
DeepSeek R1
DeepSeek-R1 的训练过程分为4个阶段,包括使用数千高质量CoT示例进行SFT的冷启动,面向推理的强化学习,通过拒绝抽样的SFT,面向全场景任务的强化学习与对齐。
两个SFT阶段进行推理和非推理能力的能力植入,两个强化学习阶段旨在泛化学习推理模式并与人类偏好保持一致。
模型下载
将下面脚本deepseek-ai/DeepSeek-R1-Distill-Qwen-32B替换成实际下载模型文件。
git clone https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
或者
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --local-dir ./
推理服务部署
SGLang部署DeepSeek-R1-Distill-Qwen-32B模型服务
# Pull latest image
# https://hub.docker.com/r/lmsysorg/sglang/tags
docker pull lmsysorg/sglang:latest
# Launch
docker run --gpus all --shm-size 50g -p 30000:30000 -v ~/.cache/huggingface:/root/.cache/huggingface --ipc=host lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tp 8 --trust-remote-code --port 30000
vLLM部署
vllm serve /root/.cache/huggingface/DeepSeek-R1-Distill-Qwen-32B --dtype auto --api-key 123 --port 30002 --served-model-name DeepSeek-R1-Distill-Qwen-32B --gpu-memory-utilization 0.4 --enforce-eager --max-model-len 32000 --tensor-parallel-size 2 --enable-reasoning --reasoning-parser deepseek_r1
推理性能对比
Docker多节点部署DeepSeek-V3
有两个 H200 节点,每个节点有 8 个 GPU。第一个节点的 IP 是 192.168.114.10,第二个节点的 IP 是 192.168.114.11。使用 --host 0.0.0.0 和 --port 40000 配置端点以将其公开给另一个 Docker 容器,并设置与 --dist-init-addr 192.168.114.10:20000 .带有 8 个设备的单个 H200 可以运行 DeepSeek V3,双 H200 设置仅用于演示多节点使用。
Node1
# node 1
docker run --gpus all \
--shm-size 32g \
--network=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--name sglang_multinode1 \
-it \
--rm \
--env "HF_TOKEN=$HF_TOKEN" \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3 --tp 16 --dist-init-addr 192.168.114.10:20000 --nnodes 2 --node-rank 0 --trust-remote-code --host 0.0.0.0 --port 40000
Node2
# node 2
docker run --gpus all \
--shm-size 32g \
--network=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--name sglang_multinode2 \
-it \
--rm \
--env "HF_TOKEN=$HF_TOKEN" \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3 --tp 16 --dist-init-addr 192.168.114.10:20000 --nnodes 2 --node-rank 1 --trust-remote-code --host 0.0.0.0 --port 40000
内存不足优化
通过优化 --chunked-prefill-size、--mem-fraction-static、--max-running-requests 来避免内存不足。
如果您看到内存不足 (OOM) 错误,可以尝试优化以下参数。
- 如果在预填充期间发生 OOM,请尝试将
--chunked-prefill-size减少到 4096 或 2048。 - 如果在解码过程中发生 OOM,请尝试减少
--max-running-requests。 - 您还可以尝试减少
--mem-fraction-static,这可以减少 KV 缓存内存池的内存使用量,并有助于预填充和解码。
其他部署参数说明
- 要启用多 GPU 张量并行,请添加
--tp 2。如果报错 “not supported peer access between these two devices”,请在服务器启动命令中添加--enable-p2p-check。 - 如果您在提供期间看到内存不足错误,请尝试通过设置较小的
--mem-fraction-static值来减少 KV 缓存池的内存使用量。默认值为0.9 -
如果您在预填充长提示期间看到内存不足错误,请尝试设置较小的
--chunked-prefill-size 4096分块预填充大小。 -
要启用 torch.compile 加速,请添加
--enable-torch-compile。它可加速小批量的小模型。这目前不适用于 FP8。 -
要启用 fp8 权重量化,请在 fp16 检查点上添加
--quantization fp8或直接加载fp8检查点,而不指定任何参数。 -
要启用 fp8 kv 缓存量化,请添加
--kv-cache-dtype fp8_e5m2 -
要在多个节点上运行张量并行,请添加
--nnodes 2。如果您有两个节点,每个节点上有两个 GPU,并且想要运行 TP=4,让sgl-dev-0作为第一个节点的主机名,让 50000作为可用端口,您可以使用以下命令。如果遇到死锁,请尝试添加--disable-cuda-graph注意:sgl-dev-0可替换成主机IP或真实的主机名称。
# Node 0
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --tp 4 --dist-init-addr sgl-dev-0:50000 --nnodes 2 --node-rank 0
# Node 1
python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --tp 4 --dist-init-addr sgl-dev-0:50000 --nnodes 2 --node-rank 1
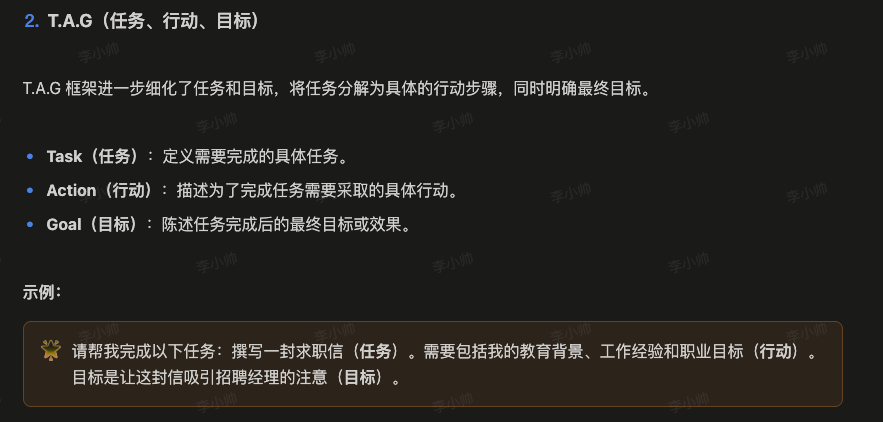
提示词技巧




引用
DeepSeek R1部署指南
sglang/benchmark/deepseek_v3 at main · sgl-project/sglang (github.com)
SGLang后端参数说明