对于语音合成项目,数据预处理对最终合成效果至关重要,这里总结梳理下常用音频编辑软件数据处理方法。
Table of Contents
这篇文档主要介绍Audacity、OcenAudio和SpleeterGUI音频编辑软件,涉及音频切片、人声分离、音频降噪及编码率和位深的修改内容。
下载资源
Audacity: https://www.audacityteam.org/download/
OcenAudio: http://www.dayanzai.me/ocenaudio.html
SpleeterGUI: https://makenweb.com/SpleeterGUI
Audacity篇
格式转换
本项目保存文件格式为wav(波形文件,录音棚黄金标准),文件另存为或者导出选择wav即可。
单声道
选中文件名——》分离立体声到单声道
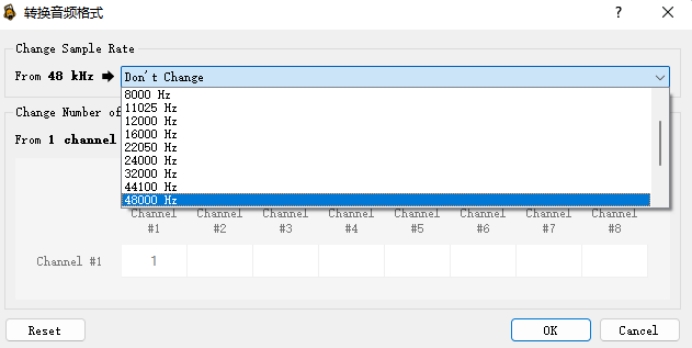
编码率
选中文件名——》采样率——》选择合适采样率。
这里不要一次对采样率参数大幅度缩放,比如原始48K,目标设为16k,不要一次设置完成。最佳操作是:48k->44k->32k->22k->16k,分步逐次缩放,不至用力过猛损坏了音频文件。
静音
选中音频,点击音频左侧的静音按钮。
采样率
1,左下角调整采样率,按照要求调整采样率。本项目调整为16K。
2,选中文件名——》采样率,调整大小。
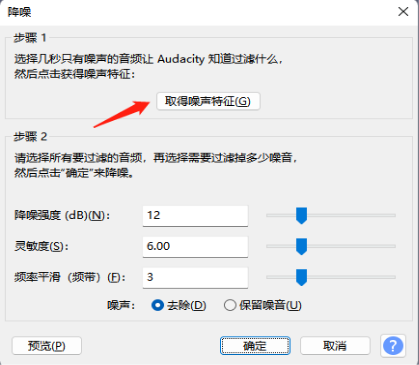
降噪
选中噪音片段,点击菜单——》效果——》Noise Removal and Repair——》降噪
第一步骤【取得噪声特征】
第二步骤选中全部音频文件,执行:点击菜单——》效果——》Noise Removal and Repair——》降噪——》确定即可(上面步骤已经取得了噪声的特征,这一步不用再点击【取得噪声特征】)
音频合并
选中不同的音轨,复制选中部分,粘贴到合适音轨上,同时把原来复制那段音频静音掉。
多文件拆分
音频拆分非常重要,从模型训练上总结的最佳实践路径是将长时长音频文件拆分成2-10秒的音频文件。
拆分方法:
1,选中2-10秒左右的音频区间
2,点击菜单栏【编辑】——》【标签】——》【为选区添加标签(快捷键Ctrl+B)】
3,重复1和2步骤,直到整个音频文件都被添加上标签。
在打标签时建议养成及时保存修改的习惯(Ctrl+S),如同Office操作一样。

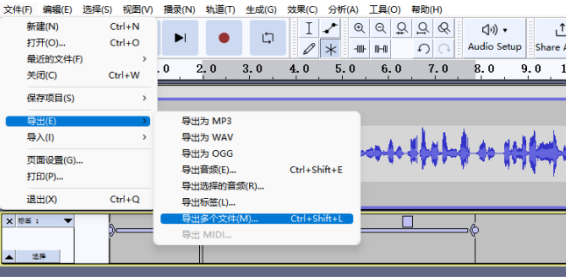
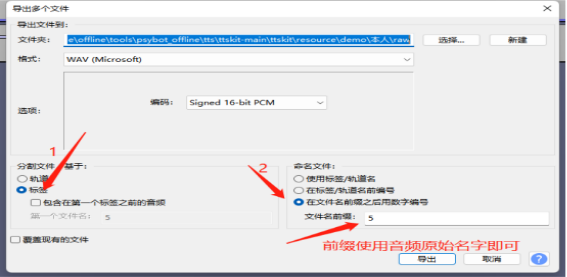
4,点击菜单栏【文件】——》【导出】——》【导出多个文件】
SpleeterGUI篇
该软件是用来分离人声与背景音的工具,使用较为简单。
背景音分离
1,设定音频文件分离几种声音类型(根据音频声音而定,单纯是人讲话录音文件,设定2即可)
2,设置人声分离后的文件存储目录
3,待处理文件路径
填写以上内容后软件自动执行人声分离。

Ocenaudio篇
该软件主要使用的功能是修改音频采样率,这个功能使用起来比Audacity软件相对好些。另一点是Ocenaudio软件能够查看到真实的编码率大小,而Audacity软件存在缺陷,无法获取真实编码率。
采样率
选中音频,鼠标右键,点击采样类型转换,如下图。
同Audacity软件一样,必须逐次降低采样率,不能一次性调整到最小采样率。