ChatGPT是一种基于 GPT 3 语言模型的对话系统技术。它使用了GPT-3模型中的一个子集,能够在回答问题的同时进行上下文延伸,表现出较好的人类化特征。
ChatGPT 技术可以应用于客服聊天机器人、智能问答系统、语音语义理解等领域。它能够根据用户输入的文本返回人类化的响应,提高用户体验。
Tables of Content
ChatGPT是什么
预训练语言模型
预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,期望模型能够获得语言相关的知识,比如句法,语法知识等等。经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大。
微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。
预训练模型示例
以BERT为例,BERT是在海量数据中进行训练的,预训练阶段包含两个任务:MLM(Masked Language Model)和NSP (Next Sentence Prediction)。前者类似”完形填空”,在一句中扣出一个单词,然后利用这句话的其他单词去预测被扣出的这个单词;后者是给定两句话,判断这两句话在原文中是否是相邻的关系。
BERT预训练完成之后,后边可以接入多种类型的下游任务,例如文本分类,序列标注,阅读理解等等,通过在这些任务上进行微调,可以获得比较好的实验结果。
OpenAI GPT原理
2018 年 6 月,OpenAI 发表论文介绍了自己的语言模型 GPT,GPT 是“Generative Pre-Training”的简称,它基于 Transformer 架构,GPT模型先在大规模语料上进行无监督预训练、再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式。
以一种半监督的方式来处理语言理解的任务,用非监督的预训练和监督方式的微调。
模型学习一个通用的语言标示,可以经过很小的调整就应用在各种任务中。这个模型的设置不需要目标任务和非标注的数据集在同一个领域。
先训练一个通用模型,然后再在各个任务上调节,这种不依赖针对单独任务的模型设计技巧能够一次性在多个任务中取得很好的表现。
OpenAI GPT训练
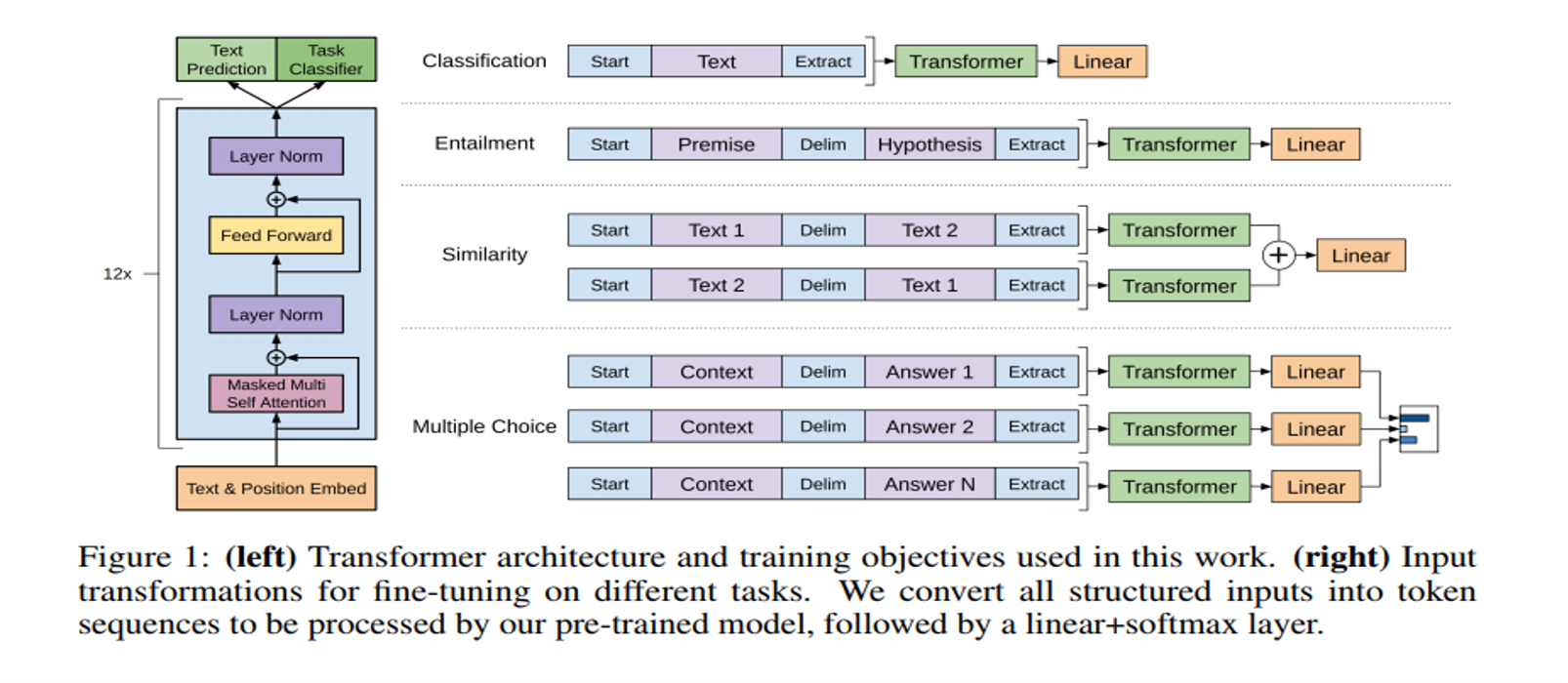
用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。
在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding。
在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。
OpenAI GPT无监督阶段
具体来说,给定一个未标注的预料库U={u1,u2,…,un},我们训练一个语言模型,对参数进行最大(对数)似然估计:
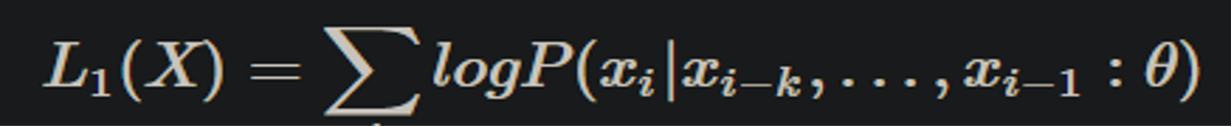
使用多层Transformer的decoder的语言模型。这个多层的结构应用masked multi-headed self-attention在处理输入的文本加上位置信息的前馈网络,输出是词的概念分布。
OpenAI GPT监督精调阶段
这个阶段要对前一个阶段模型的参数,根据监督任务进行调整。我们假设有标签数据集C,里面的结构是(x1,x2,…,xm,y)。输入(x1,x2,…,xm)经过我们预训练的模型获得输出向量h,然后经过线性层和softmax来预测标签。
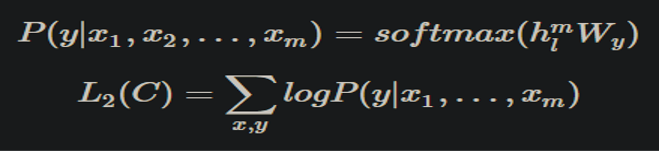
我们增加了语言模型去辅助微调,提高了监督模型的结果。最后的损失函数可以标示为
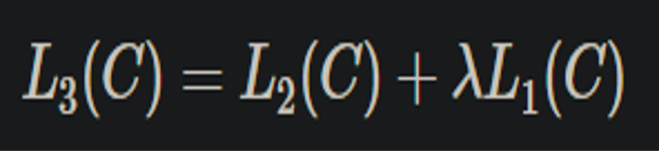
OpenAI GPT模型结构
InstructGPT
面向意图一致的语言模型对齐。让语言模型变大并不能从本质上使它们更好地遵循用户的意图。例如,大型语言模型可以产生不真实的、有毒的、或者根本对用户没有帮助的输出。换句话说,这些模型没有与用户保持一致。
InstructGPT展示了一种途径,通过人工反馈的微调,在广泛的任务中使语言模型与用户意图相一致。为了让模型更安全、更有用、更一致,OpenAI 使用了一种称为从人类反馈中强化学习(RLHF,Reinforcement Learning from Human Feedback)的现有技术。根据客户向 API 提交的反馈,OpenAI 对模型的多个输出进行排序。然后,OpenAI 使用这些数据来微调 GPT-3。
由此产生的 InstructGPT 模型,在遵循指令方面,远比 GPT-3 要好得多。而且,它们也较少的凭空捏造事实,有害输出的产生呈现小幅下降趋势。InsructGPT 的参数量为 1.3 B。
强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
智能体(agent):智能体是强化学习算法的主体,它能够根据经验做出主观判断并执行动作,是整个智能系统的核心。
环境(environment):智能体以外的一切统称为环境,环境在与智能体的交互中,能被智能体所采取的动作影响,同时环境也能向智能体反馈状态和奖励。虽说智能体以外的一切都可视为环境,但在设计算法时常常会排除不相关的因素建立一个理想的环境模型来对算法功能进行模拟。
强化学习基础概念
动作(action):动作是智能体对环境产生影响的方式,这里说的动作常常指概念上的动作,如果是在设计机器人时还需考虑动作的执行机构。
策略(policy):策略是智能体在所处状态下去执行某个动作的依据,即给定一个状态,智能体可根据一个策略来选择应该采取的动作。
奖励(reward):奖励是智能体贯式采取一系列动作后从环境获得的收益。注意奖励概念是现实中奖励和惩罚的统合,一般用正值来代表奖励,用负值代表实际惩罚。
状态(state):状态可以理解为智能体对环境的一种理解和编码,通常包含了对智能体所采取决策产生影响的信息。
强化学习示例
在flappy bird游戏中,小鸟即为智能体,除小鸟以外的整个游戏环境可统称为环境,状态可以理解为在当前时间点的游戏图像。
智能体可以执行的动作为向上飞,或什么都不做靠重力下降。
策略则指小鸟依据什么来判断是要执行向上飞的动作还是什么都不做。
奖励分为奖励和惩罚两种,每当小鸟安全的飞过一个柱子都会获得一分的奖励,而如果小鸟掉到地上或者撞到柱子则或获得惩罚。

ChatGPT原理
主要参考自instructGPT的论文,ChatGPT是改进的instructGPT,改进点主要在收集标注数据方法上有些区别,在其它方面,包括在模型结构和训练流程等方面基本遵循instructGPT。
整体技术路线上,ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback ,这里的人工反馈其实就是人工标注数据)来不断Fine-tune精调预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
ChatGPT训练
具体而言,在“人工标注数据+强化学习”框架下,ChatGPT的训练过程分为以下三个阶段:
第一阶段:冷启动阶段的监督策略模型
第二阶段:训练回报模型(Reward Model,RM)
第三阶段:采用强化学习来增强预训练模型的能力
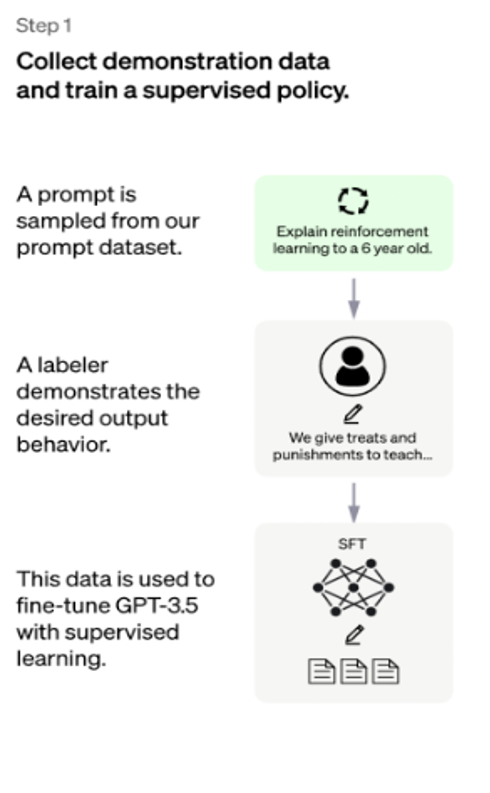
ChatGPT冷启动阶段
为了让GPT 3.5初步具备理解指令中蕴含的意图,首先会从测试用户提交的prompt(就是指令或问题)中随机抽取一批,靠专业的标注人员,给出指定prompt的高质量答案,然后用这些人工标注好的<prompt,answer>数据来Fine-tune GPT 3.5模型。
ChatGPT回报训练阶段
这个阶段的主要目的是通过人工标注训练数据,来训练回报模型。具体而言,随机抽样一批用户提交的prompt(大部分和第一阶段的相同),使用第一阶段Fine-tune好的冷启动模型,对于每个prompt,由冷启动模型生成K个不同的回答,于是模型产生出了<prompt,answer1>,<prompt,answer2>….<prompt,answerk>数据。之后,标注人员对K个结果按照很多标准(上面提到的相关性、富含信息性、有害信息等诸多标准)综合考虑进行排序,给出K个结果的排名顺序,这就是此阶段人工标注的数据。</prompt,answerk></prompt,answer2></prompt,answer1>。
接下来,我们准备利用这个排序结果数据来训练回报模型,采取的训练模式其实就是平常经常用到的pair-wise learning to rank。对于K个排序结果,两两组合,ChatGPT采取pair-wise loss来训练Reward Model。
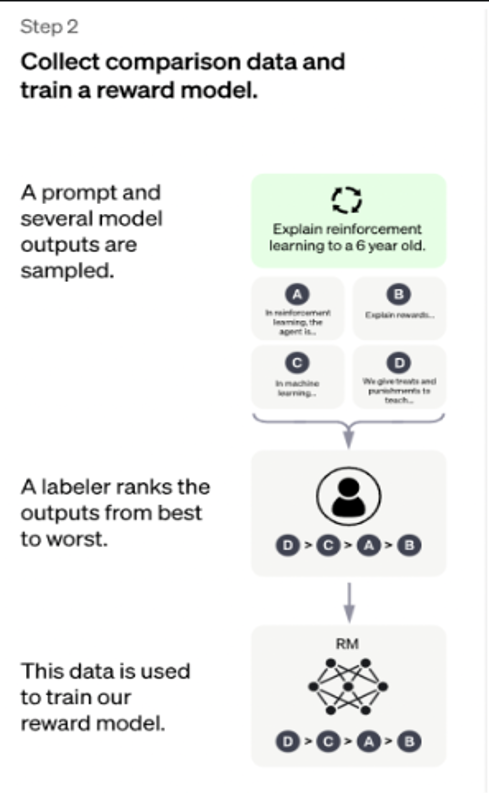
ChatGPT强化学习增强阶段
本阶段无需人工标注数据,而是利用上一阶段学好的RM模型,靠RM打分结果来更新预训练模型参数。
具体而言,首先,从用户提交的prompt里随机采样一批新的命令(指的是和第一第二阶段不同的新的prompt,这个其实是很重要的,对于提升LLM模型理解instruct指令的泛化能力很有帮助),且由冷启动模型来初始化PPO模型的参数。然后,对于随机抽取的prompt,使用PPO模型生成回答answer, 并用上一阶段训练好的RM模型给出answer质量评估的回报分数score,这个回报分数就是RM赋予给整个回答(由单词序列构成)的整体reward。有了单词序列的最终回报,就可以把每个单词看作一个时间步,把reward由后往前依次传递,由此产生的策略梯度可以更新PPO模型参数。
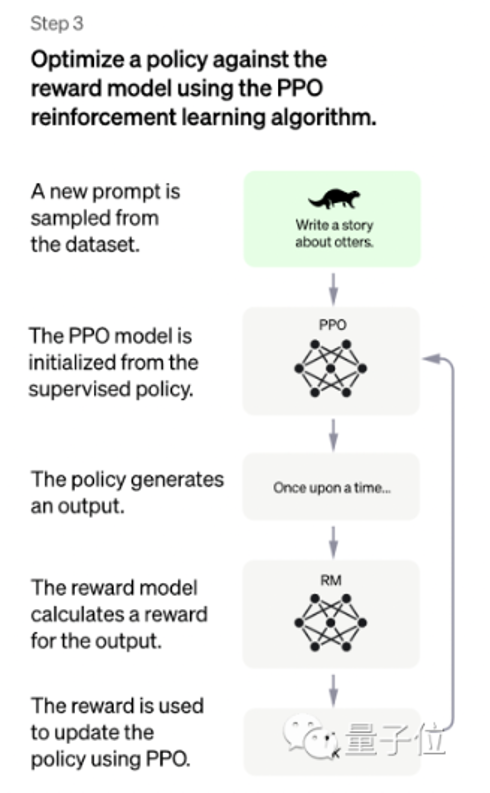
ChatGPT训练过程
如果我们不断重复第二和第三阶段,很明显,每一轮迭代都使得LLM模型能力越来越强。因为第二阶段通过人工标注数据来增强RM模型的能力,而第三阶段,经过增强的RM模型对新prompt产生的回答打分会更准,并利用强化学习来鼓励LLM模型学习新的高质量内容,这起到了类似利用伪标签扩充高质量训练数据的作用,于是LLM模型进一步得到增强。
显然,第二阶段和第三阶段有相互促进的作用,这是为何不断迭代会有持续增强效果的原因。
风险与挑战
数据隐私和安全。由于 chatGPT 涉及到大量的个人信息,因此如果不加以保护,就有可能被黑客攻击和泄露。
对于不少知识类型的问题,chatGPT会给出看上去很有道理,但是事实上是错误答案的内容。考虑到对于很多问题它又能回答得很好,这将会给用户造成困扰:如果我对我提的问题确实不知道正确答案,那我是该相信ChatGPT的结果还是不该相信呢?此时你是无法作出判断的。这个问题可能是比较要命的。
一些评价
Hacker News上用户发现ChatGPT对编程问题的回答往往是错误的。“可怕的是,它说出错误答案时是那么自信,文字看起来很好,但里面有很大的错误。”
StackOverflow已暂时禁止用户张贴ChatGPT生成的回答,表示:ChatGPT 只是让用户很容易生成响应,并在网站上充斥着乍一看似乎正确的答案,但在仔细检查时往往是错误的。
还有很多惊叹于逆天技术,担忧人类某天被人工智能替代、甚至控制。
对话例子