深度语义结构模型(Deep Semantic Structured Model,DSSM)是最早将深度模型应用在文本匹配的工作之一。
问题描述
首先给定标注训练数据集合\(S_{train} = \{(s_1^{(i)},s_2^{(i)},r^{(i)})\}_{i=1}^N\),其中\(s_1^{(i)} \in S_1, \space s_2^{(i)} \in S_2\)为两段文本,例如在搜索引擎中,两者分别为查询项和文档;而在问答系统中,两者分别为问题和答案,\(r^{(i)} \in R\)表示对象\(s_1^{(i)}\)和\(s_2^{(i)}\)的匹配程度。文本匹配是目的是在训练数据上,自动学习匹配模型f:\(S_1 * \space S_2 \space \to R\),使得对于测试数据上的任意输入\(s_1 \in S_1, \space s_2 \space \in S_2\)能够预测出\(s_1, \space s_2\)间的匹配程度,然后根据匹配程度排序得出结果。
例如:
s1: 从古至今,面条和饺子是中国人喜欢的食物
s2:从古至今,饺子和面条在中国都是人见人爱
那么判断s1和s2是否匹配就是我们的结论r。在上面这个问题就是看两个句子是否表达了同一个意思。在问答系统中是否匹配就是看第二个句子是否是第一个句子的答案。因此,不同的任务,匹配的概念定义不同的。
评价指标
衡量一个排序结果优劣的评价指标主要包括\(Precision 、Recall、MRR、MAP、nDCG\)等,可见评价指标。
基于深度学习的文本匹配学习模型
针对深度文本匹配模型,通常包括如下几个关键操作。我们定义\(s_1 = \{x_i\}_{i=1}^n, \space s_2 = \{y_i\}_{i=1}^m\)表示文本样本\(s_1\)和\(s_2\)中的单词序列,其中n和m表示句子长
度,\(x_i, \space y_i\)表示句子中的单词。
(1)单词表达。函数\(w_i = \phi(x_i), \space v_i = \phi(y_i)\)表示单词\(x_i, y_i\)得到的词向量\(w_i, v_i\)的一个映射.整个句子映射后得到矩阵\(w, v\)。
(2)短语/句子表达。利用函数\(p=\Phi(w), q=\Phi(v)\)得到短语或者整个句子的表达。
以上两步操作,我们都是处理的单个句子的语义表示问题,所以最后得到的表达或者中间的表达不仅仅可以用于文本匹配问题,还可以用于文本分类聚类问题。接下来是文本匹配任务特有的语义交互步骤。
(3)文本交互。用\(M_0\)表示两段文本交互后的结果,我们定义\(M_0 = f(p, q)\)。
(4)匹配空间内的模式提取。在得到基本交互信息的基础上进一步提取匹配空间的模式信息,可以表示为函数\(M_k = g(M_{k-1})\)这里的函数g可以由多个函数级联而成。
(5)匹配程度得分.最后一步旨在综合前面的信息,得到一个匹配程度的打分,也即\(r=h(M_n)\)。
基于全连接神经网络
深度语义结构模型(Deep Semantic Structured Model,DSSM)是最早将深度模型应用在文本匹配的工作之一。该模型主要针对查询项和文档的匹配度进行建模,相对于传统文本匹配的模型,该方法有显著的提升。深度语义结构模型是典型的孪生网络结构,每个文本对象都是由5层的网络单独进行向量化的,最后计算两个文本向量的余弦相似度来决定这两段文本的相似程度。
下图深度语义结构模型
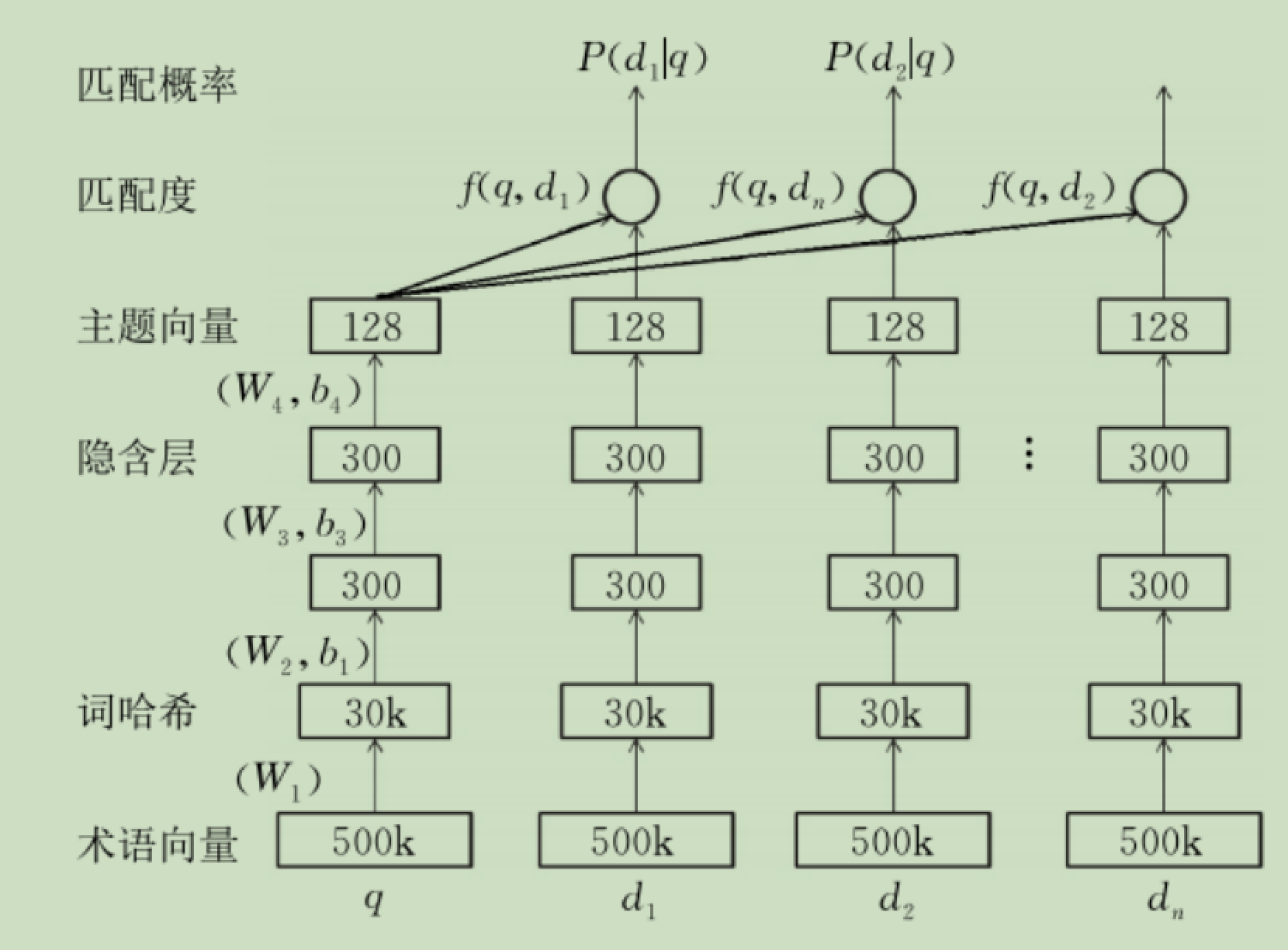
深度语义结构模型在文本向量化的时候分成了两个主要部分:第1部分是将文本中的每个单词,或者是由3个字母组成的片段做成一个最小单元,通过哈希方式映射到一个单词(字母片段)级别的向量,见图中的词哈希层。基于得到的单词向量,深度语义结构模型接上了3层的全连接来表达整个句子的主题向量,这个向量有128个维度。整个模型在训练的时候使用了大量的搜索系统的点击日志数据,其中点击的作为正样本,并从没有点击的里面随机抽样一定量的负样本。然后正负样本组成一组,通过softmax函数计算每个文档和查询项的匹配概率,然后最大化所有正例的匹配概率的似然函数。似然函数如下:
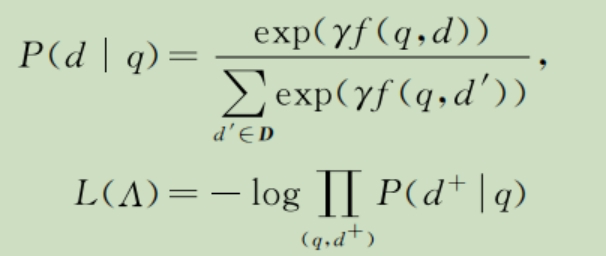
基于卷积神经网络
微软研究团队在成功提出深度语义结构模型之后,发现全连接的神经网络的参数太多,不利于优化,而且构造输入数据利用的是词袋模式,忽略了词与词之间序的关系,对于匹配这种局部信息很强的任务,没法将一些学到的局部匹配信息应用到全局。
于是进一步改进模型,提出了基于单词序列的卷积深度语义结构模型(Convolutoinal Deep Semantic Structured Model)。卷积深度语义结构模型相对于深度语义结构模型,将中间生成句子向量的全连接层换成了卷积神经网络的卷积层(Convolutional Layer)和池化层(Pooling Layer),如下图,其它的结构和深度语义结构模型是一样的。
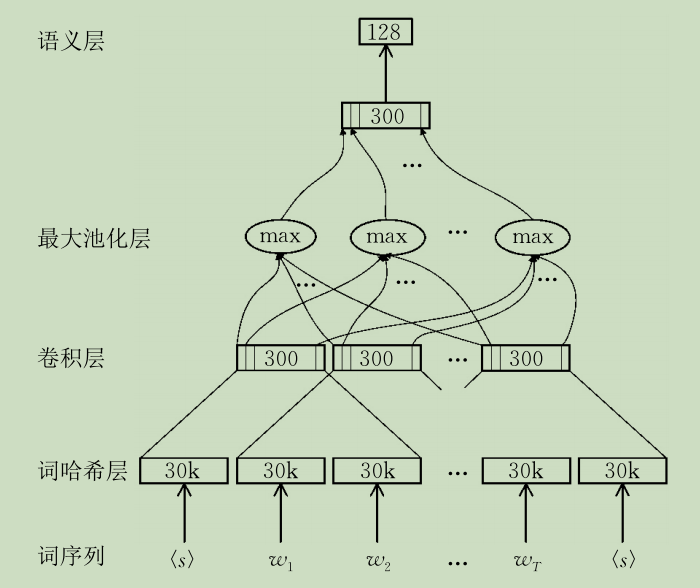
卷积深度语义结构模型首先将查询项与文档中的每个单词(字母片段)都表示为一个词向量,然后对每个固定长度的窗口内的词向量进行卷积操作,得到针对这个窗口内短语的一个向量表达,之后卷积深度语义结构模型在这些卷积得到的向量上进行全局的池化操作,即对所有窗口输出的向量的相同位置取最大值。由于卷积的滑动窗口的结构形式考虑到了句子中的单词顺序信息,在相关度判断的准确度方面相对于深度语义结构模型有了一定的提升。
基于循环神经网络
为解决基于卷积神经网络没法捕捉句子长距离的依存关系的问题,微软研究团队Palangi等人提出基于长短时记忆(Long Short Term Memory)的文本匹配模型。具体地来说,查询项和文档分别经由长短时记忆的循环神经网络表达为一个向量,然后计算两个向量表达的余弦距离作为相似度的度量,输出最终的匹配值。该方法在网页搜索的在线日志数据上取得了不错的效果。