在传统神经网络模型中,从输入层到隐藏层再到输出层,层与层之间是全连接的,每层之间的点是无连接的。
序列模型RNN
在传统神经网络模型中,从输入层到隐藏层再到输出层,层与层之间是全连接的,每层之间的点是无连接的。在RNN模型中,神经元的输出可以在下一时刻直接作用到自身,即第i层神经元在t时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(t-1)时刻的输出。另外,理论上RNN能够对任何长度的序列数据进行处理。但在实践当中,为了降低模型复杂性往往假设当前的状态只与前面的几个状态相关。这也在一定程度上造成了RNN记忆力越往前越弱,越往后越强的情况。
注意力机制原理
Attention机制直接跳出了上述RNA循环序列前后依赖的问题,这样的结构解放了模型并行计算受限的困扰。从字面意思上就可以看出,注意力机制模拟人类接触信号的方式。人只关注重点部分而不是全量信息,对重点部分的信息给予更多的注意力,在数学模型中即给予更高的权重值。比方出看图说话时,我们要求模型用一句话描述一副图片的内容,模型所生成的词语应该对应图中的不同部分。当解码器进行解码时,应该给图中“合适”的部分分配更多的注意力和权重。在Encoder-Decoder范式中,编码器把所有的输入序列都编码成一个统一的语义编码层c再解码。c中必须包含原始序列中的所有信息。它的长度就成了限制模型性能的瓶颈。如机器翻译问题。当要翻译的句子较长,是一个c可能存不下那么多的信息就会造成翻译精度下降。
Attention机制通过在每一个时间输入不同的语义编码\(c_i\)来解决这个问题。如图a表示带有Attention机制的Decoder。每一个\(c_i\)会自动选取与当前所要输出\(y_i\)最合适的上下位信息。具体来讲,上下文信息\(c_i\)就来自所有\(h_j\)对\(a_{ij}\)的加权和,这些权重\(a_{ij}\)同样是从模型中学习出来的。
以中英文翻译为例,输入的序列是“我爱吃苹果”。Encoder中的\(h_i={h_1, h_2, h_3, h_4, h_5}\)就可以看成是“我”“爱”“吃”“苹”“果”所代表的信息,第一个上下文\(c_i\)的值是\(h_i\)与\(a_1={a_{11},a_{12},a_{13},a_{14},a_{15}}\)元素的加权求和的结果。在翻译成英文时,\(c_1\)和“我”这个字最相关的\(a_{11}\)值就比较大,而相应的\(a_{12}\)、\(a_{13}\)、\(a_{14}\)、\(a_{15}\)值就比较小。一直类推,上下文\(c_i\)关注了所有可能的因素,只是Attention权重不一样。这样就能让模型学出不同语境中“苹果”的含义了。翻译的计算过程如下,*表示点乘。
\[h_1 * a_{11} + h_2 * a_{12} + h_3 * a_{13} + h_4 * a_{14} + h_5 * a_{15} = c_1 \to I\] \[h_1 * a_{21} + h_2 * a_{22} + h_3 * a_{23} + h_4 * a_{24} + h_5 * a_{25} = c_1 \to Love\] \[h_1 * a_{31} + h_2 * a_{32} + h_3 * a_{33} + h_4 * a_{34} + h_5 * a_{35} = c_1 \to Apples\]Self-Attention机制
Attention机制通常用在Encoder的和Decoder之间,它缓解了中间语义层C的信息损失问题。Self-Attention自注意力机制源于attention。但他的根本目标是为了增强文本的语义表达。Self-Attention机制计算中涉及到Query、Key和Value三个概念。
Self-Attention单字计算
1、计算Query、Key、Value向量
为编码器的每个输入token向量(这个例子中是每个词的词嵌入表示)创建三个向量。对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过将词嵌入(embedding)乘以在训练过程中训练的三个矩阵来创建的。
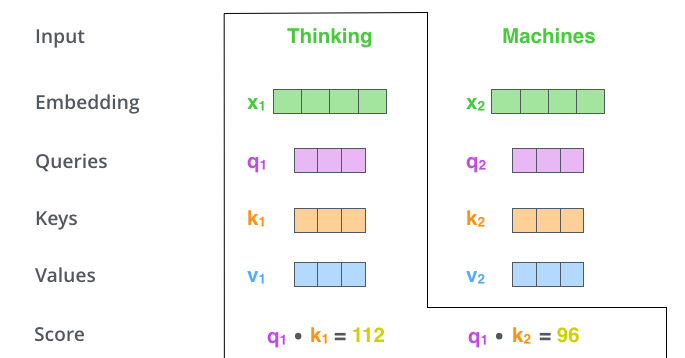
将X1乘以矩阵WQ将产生q1。也就是与该单词有关的“Query”向量。最终为输入句子中的每个单词创建了“query”,“key”,“value”向量。
2、计算权重得分score
假设我们正在计算例子中第一个单词”Thinking”的self-attention。我们需要根据这个词对输入句子的每个词进行评分。当我们在某个位置处编码单词时,权重得分的大小决定了对输入句子的其他部分放置多少的焦点(注意力)。
这里的权重得分是通过将”query”向量与我们正在评分的单词的“key”向量做点积来得到。所以如果我们计算位置#1处的单词的self-attention,第一个得分就是就是q1和k1的点积。第二个得分是q1和k2的点积。
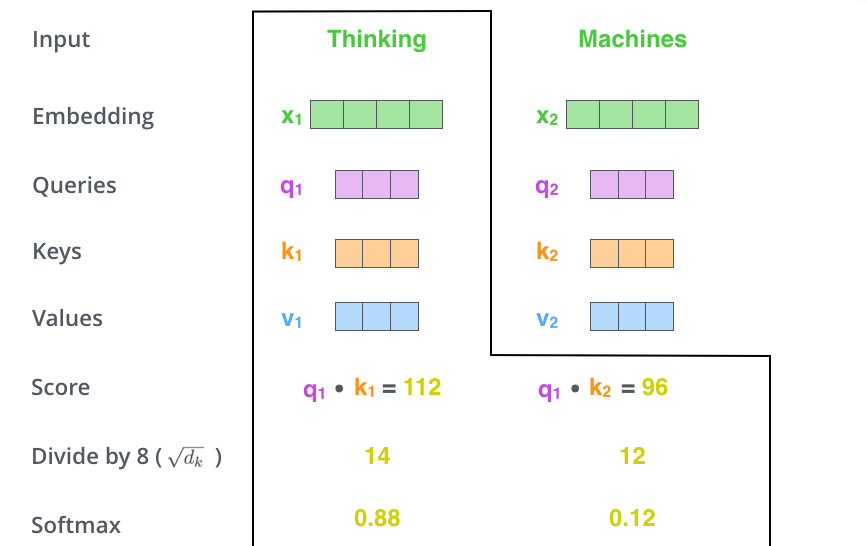
3、权重得分归一化和稳梯度
将权重得分score除以8(论文中使用“Key”向量维数的平方根—64。这可以有更稳定的梯度。实际上还可以有其他可能的值,这里使用默认值),然后经过一个softmax操作后输出结果。Softmax可以将分数归一化,这样使得结果都是正数并且加起来等于1。softmax后的分数决定了每个单词在这个位置被表达了多少。很明显该位置的这个词具有最高的softmax分数,但是有时候关注与当前词相关的其它词更有用。
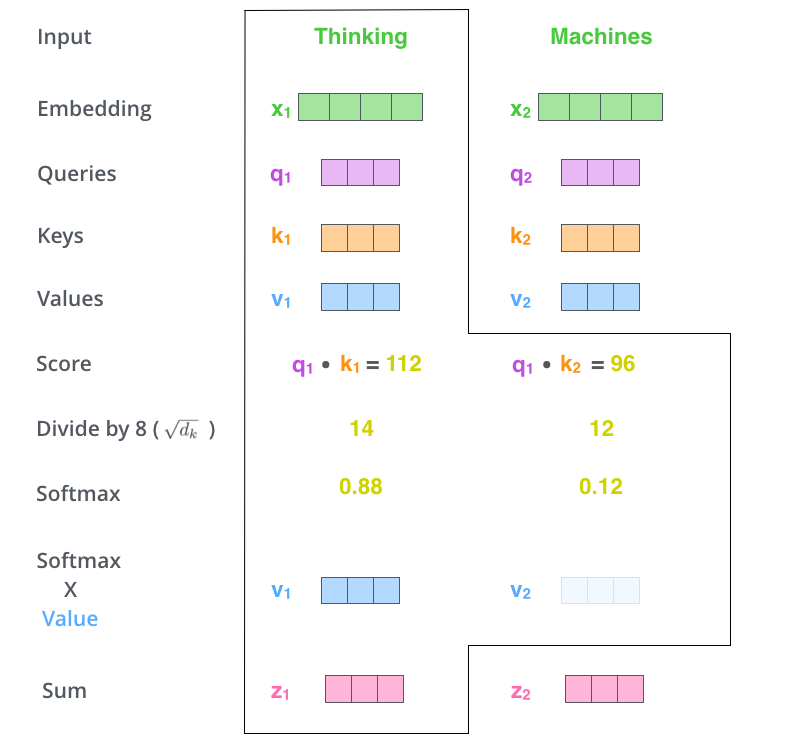
4、Values向量的更新
将每个Values向量乘以softmax后的权重得分。直觉上讲需要保持我们关注的单词的值不变,忽略掉不相关的单词(比如可以将它们乘以0.001这样的小数字)。
5、Values向量加权和
对加权values向量求和。这样就产生了在这个位置的self-attention的输出(对于第一个单词)。
这就是self-attention计算。得到的向量可以送往前馈神经网络。然而在真正的实现中,计算过程通过矩阵计算来进行,以便加快计算。
Self-Attention矩阵运算
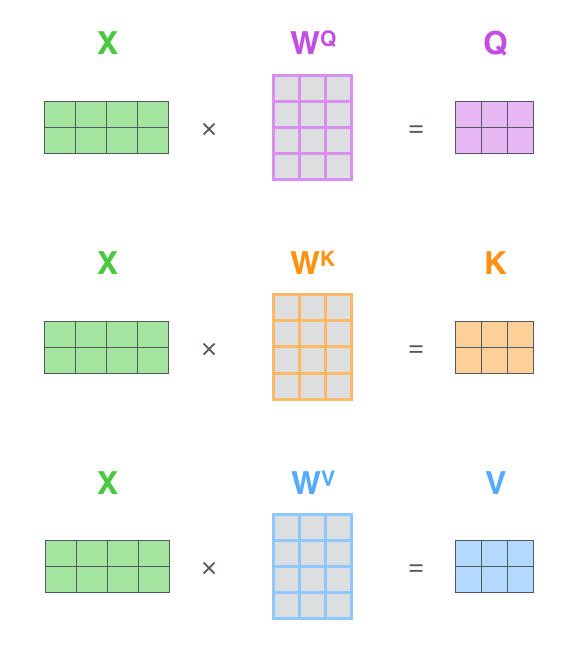
1、Query, Key, Value矩阵计算
通过将词嵌入整合到矩阵\(X\)中,并将其乘以训练过的权重矩阵(\(WQ ,\quad WK, \quad WV\))来实现。
矩阵\(X\)中每行对应于输入序列中某个单词。图中词嵌入向量的大小是4,现实往往是512, 也看到了 q/v/k 向量维度大小是3,现实往往是64)。
2、Self-Attention矩阵运算输出
通过矩阵运算将步骤2到步骤6合并为一个公式来计算self-attention层的输出。
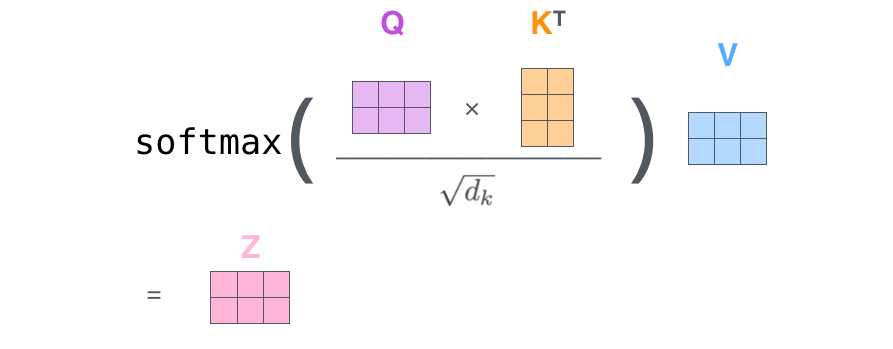
多头自注意力机制
Multi-Head Self-Attention(多头自注意力)为了增强有的Attention的多样性,进一步利用不同的self attention模块获取query中每一个字在不同语义空间下的增强语义向量。最后将每个字的增强语义向量进行线性组合,从而得到最终向量。
“多头”注意力的机制通过以下两种方式改善Self-Attention注意力层的性能:
1、它扩展了模型对不同位置的关注能力。在上面的例子中,Z1包含了每个其他编码的一点,但它可能由实际的单词本身支配。翻译句子:“The animal didn’t cross the street because it was too tired”,我们很想知道这里的“it”指代什么? 这时候会很有帮助。
2、它给予attention层多个“表达子空间”。多头注意力有多组Query/ Key /Value权重矩阵。每组集合都是随机初始化,训练后每组权重矩阵将嵌套向量映射到不同的表达子空间。