问答系统(Question Answer)是指让计算机自动回答用户所提出的问题,是信息服务的一种高级形式。
问答系统(Question Answer)是指让计算机自动回答用户所提出的问题,是信息服务的一种高级形式。不同于现有的搜索引擎返回的不再是基于关键词匹配的文档排序,而是通过语义理解的精准答案。
分析用户自然语言问题的语义,进而在已构建的结构化知识图谱中通过检索、匹配或推理等手段获取正确的答案。这种任务被称为知识库问答KBQA。这一问答范式在数据层面通过知识图谱的构建对文本内容进行的深入挖掘与理解,能够有效提升用户的准确性。
知识库问答要回答用户的问题,首先就要正确理解用户所提问题的语义内容。面对结构化知识库,需要将用户问题转化为结构化的查询语句,进而对知识库进行查询、推理等操作,获取正确答案。因此,对于用户问题的语义解析是知识库问答研究面临的科学问题。
具体过程是分析用户问题中的语义单元,与知识图谱中的实体概念进行链接、并分析用户问题中这些语义单元之间的关系。将用户问题解析成知识图谱定义的实体概念关系,最终组成结构化语义表示形式。
如示例:
Query:姚明和叶莉之间有什么关系?
Conditions:Person; Person
Values:姚明;叶莉
Results:夫妻关系
Targets:Relations
对于知识图谱Cypher查询语句:
Match (:Person{name: “姚明”}) -[r]->(:Person{name: “叶莉”}) return r.name
从上面示例不难发现的,查询中关键信息有两个:查询的目标以及查询的条件。在上述例子中,查询的条件是两个实体,且实体的属性name分别是姚明和叶莉,查询的目标是这两个人之间的关系。在我们任务中,查询的目标只有三种,分别是查询人物姓名、查询人物间的关系以及查询全部信息,因此需要创建一个分类模型,用于判别问句的查询目标。其次需要识别查询条件,也即是从查询query当中抽取可能存在的实体名称。
查询目标检测
根据上述任务的描述,采用文本分类模型针对查询目标进行识别。本次分类模型类别共有三类,如下表。
| 目标名称 | 目标id |
|---|---|
| * | 0 |
| Relation | 1 |
| Person | 2 |
文本分类模型比较多,如TextCNN、BiLSTM,还有预训练模型Bert、XLNET等都可以结合业务尝试。
查询条件抽取
实体的抽取和关系的抽取任务可以联合训练,也可以管道Pipeline分别独立训练。这里我们采用BIOS标注体系进行查询条件的联合抽取。其中N表示实体的名称,R表示关系的名称。问句中包含一个实体“姚明”,一个关系“夫妻关系”。
查询条件抽取任务转换成序列标注任务。标注方式如下:
| 与 | 姚 | 明 | 有 | 夫 | 妻 | 关 | 系 | 的 | 人 | 是 | 谁 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| O | N-B | N-E | O | R-B | R-E | O | O | O | O | O | O |
序列标注任务一般采用双向LSTM作为特征提取,近年来一些算法比赛用到了一些大的预训练模型,比如BERT、XLNET作为特征提取器。序列模型存在一定的特殊性,因此需要引入CRF记录标签间的转移矩阵,排除掉。
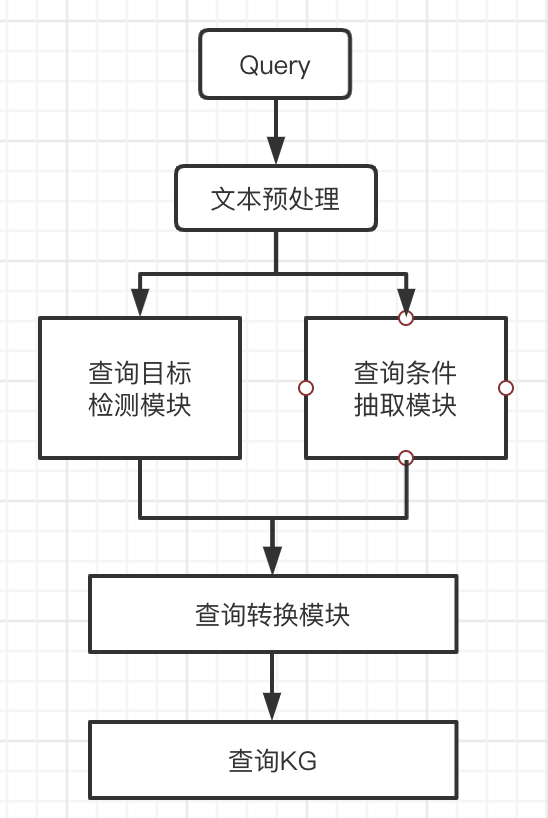
基于知识图谱查询架构图
首先对用户查询请求进行文本预处理,得到数据处理结果。分别采用目标检测模块和条件查询模块获取用户请求的查询目标和查询条件。结合查询转换模块将查询结果转化成相应的Cypher查询语句,获取知识图谱结果。